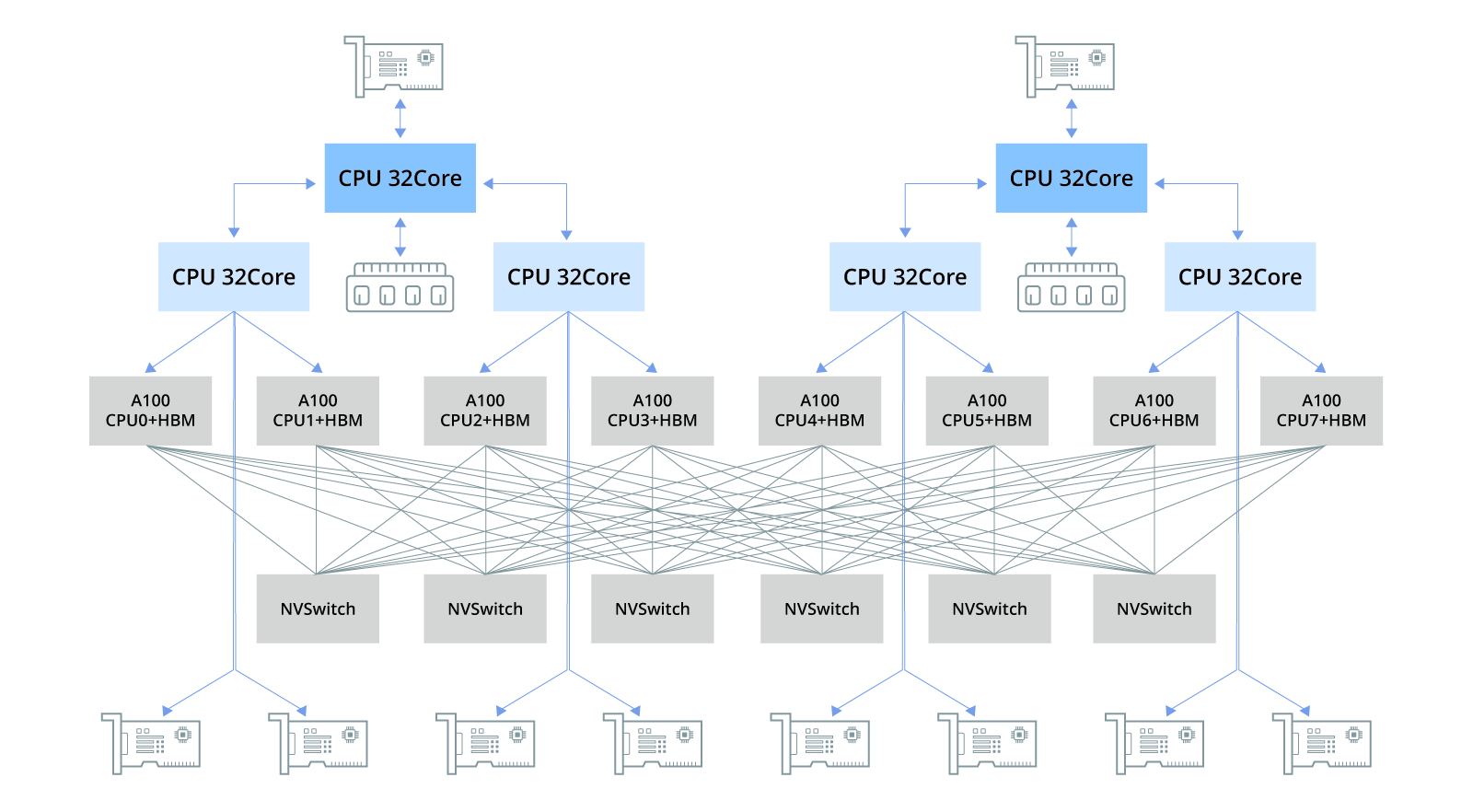
服务器内部的硬件连接拓扑结构直接影响其性能表现。以典型的8块A100 GPU服务器为例,其内部通过PCIe总线或专门设计的PCIe交换机芯片实现各组件的高效连接。PCIe历经五代技术革新,最新Gen5版本显著提升了设备间的互连性能,确保数据传输速度的大幅提升。
英伟达开发的NVLink技术在这一领域扮演着关键角色。NVLink采用点对点结构和串列传输,主要用于CPU与GPU之间以及多GPU之间的连接。与PCI Express不同,NVLink支持设备间的多通道通信,采用网格网络而非中心集线器方式,显著提高了数据传输效率。
从NVLink 1.0到NVLink 4.0,技术不断演进,连接通道数和总带宽逐步增加,从最初的160 GB/s提升至900 GB/s,极大改善了GPU间的通信效率,满足高性能计算应用的需求。
此外,NVIDIA还推出了NVSwitch交换芯片,专门用于实现同一主机内多GPU间的高速低延迟通信。NVSwitch在硬件连接拓扑中占据核心位置,确保GPU间数据传输的高效性。
在内存技术方面,传统DDR内存通过PCIe接口连接,存在带宽瓶颈。为突破这一限制,GPU制造商采用高带宽内存(HBM)技术,将多个DDR芯片堆叠整合,直接与GPU相连,大幅提升数据传输速度。
HBM技术从HBM1发展到HBM3e,带宽和性能不断提升,成为高性能计算领域的重要支撑。在评估系统性能时,需注意不同带宽单位的差异,如网络带宽通常以bit/s表示,而PCIe、内存、NVLink及HBM带宽则以Byte/s或T/s衡量,准确识别和转换带宽单位对于全面理解系统性能至关重要。
总之,高性能GPU服务器的构建涉及多种先进技术和组件的协同工作,从PCIe总线到NVLink技术,再到NVSwitch和HBM内存,每一环节都直接影响系统的整体性能,共同推动大规模模型训练的高效进行。在大规模模型训练的领域中,构建高性能GPU服务器的基础架构通常依托于由单个服务器搭载8块GPU单元所组成的集群系统。这些服务器内部配置了如A100、A800、H100或H800等高性能GPU型号,并且随着技术发展,未来可能还会整合{4, 8} L40S等新型号GPU。下图展示了一个典型的配备了8块A100 GPU的服务器内部GPU计算硬件连接拓扑结构示意图。
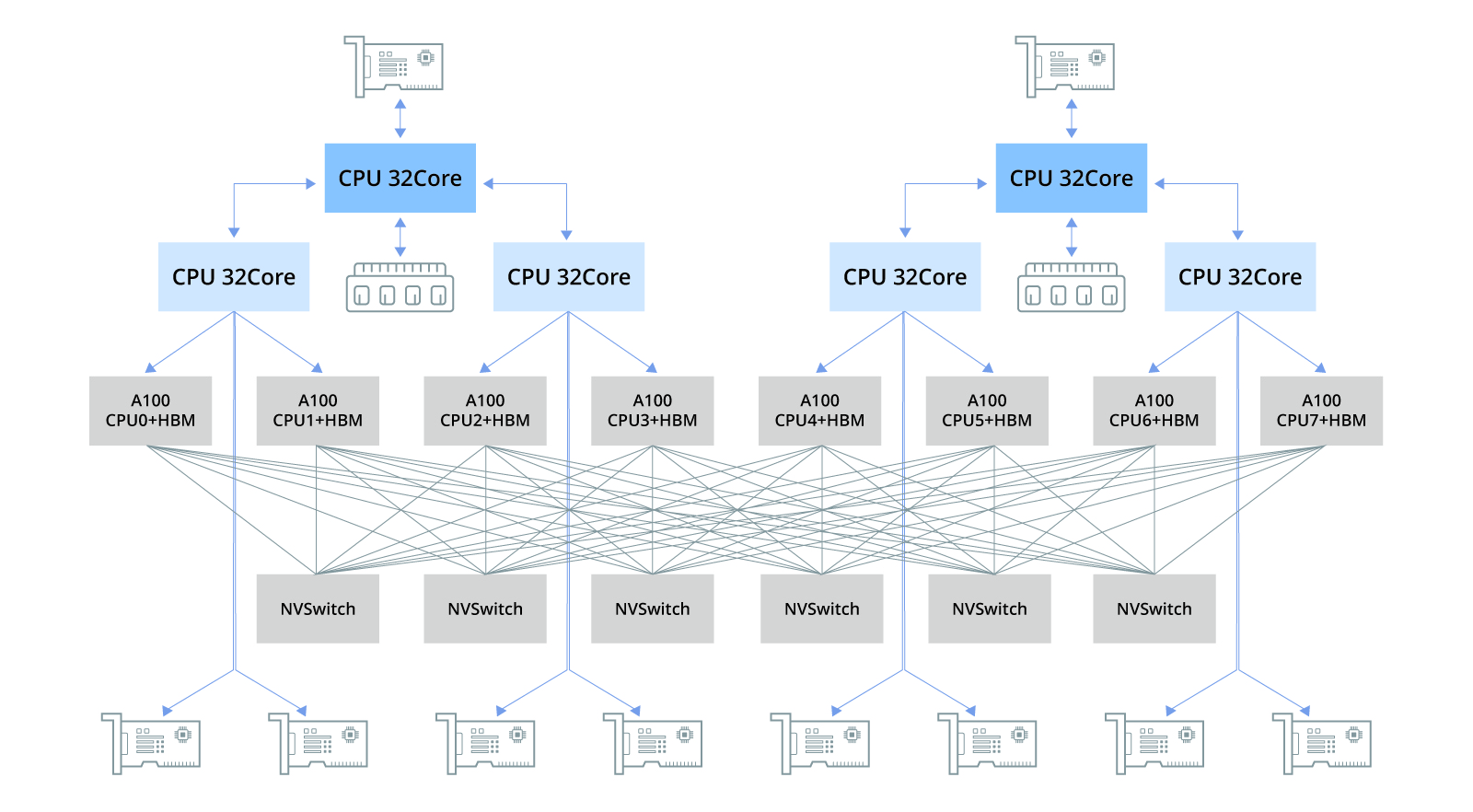 本文将依据上述图表,对GPU计算涉及的核心概念与相关术语进行深入剖析和解读。
PCIe交换机芯片
在高性能GPU计算的领域内,关键组件如CPU、内存模块、NVMe存储设备、GPU以及网络适配器等通过PCIe(外设部件互连标准)总线或专门设计的PCIe交换机芯片实现高效顺畅的连接。历经五代技术革新,目前最新的Gen5版本确保了设备间极为高效的互连性能。这一持续演进充分彰显了PCIe在构建高性能计算系统中的核心地位,显著提升了数据传输速度,并有力地促进了现代计算集群中各互联设备间的无缝协同工作。
NVLink概述
NVLink定义
NVLink是英伟达(NVIDIA)开发并推出的一种总线及其通信协议。NVLink采用点对点结构、串列传输,用于中央处理器(CPU)与图形处理器(GPU)之间的连接,也可用于多个图形处理器之间的相互连接。与PCI Express不同,一个设备可以包含多个NVLink,并且设备之间采用网格网络而非中心集线器方式进行通信。该协议于2014年3月首次发布,采用专有的高速信号互连技术(NVHS)。
该技术支持同一节点上GPU之间的全互联,并经过多代演进,提高了高性能计算应用中的双向带宽性能。
NVLink的发展历程:从NVLink 1.0到NVLink 4.0
NVLink技术在高性能GPU服务器中的演进如下图所示:
本文将依据上述图表,对GPU计算涉及的核心概念与相关术语进行深入剖析和解读。
PCIe交换机芯片
在高性能GPU计算的领域内,关键组件如CPU、内存模块、NVMe存储设备、GPU以及网络适配器等通过PCIe(外设部件互连标准)总线或专门设计的PCIe交换机芯片实现高效顺畅的连接。历经五代技术革新,目前最新的Gen5版本确保了设备间极为高效的互连性能。这一持续演进充分彰显了PCIe在构建高性能计算系统中的核心地位,显著提升了数据传输速度,并有力地促进了现代计算集群中各互联设备间的无缝协同工作。
NVLink概述
NVLink定义
NVLink是英伟达(NVIDIA)开发并推出的一种总线及其通信协议。NVLink采用点对点结构、串列传输,用于中央处理器(CPU)与图形处理器(GPU)之间的连接,也可用于多个图形处理器之间的相互连接。与PCI Express不同,一个设备可以包含多个NVLink,并且设备之间采用网格网络而非中心集线器方式进行通信。该协议于2014年3月首次发布,采用专有的高速信号互连技术(NVHS)。
该技术支持同一节点上GPU之间的全互联,并经过多代演进,提高了高性能计算应用中的双向带宽性能。
NVLink的发展历程:从NVLink 1.0到NVLink 4.0
NVLink技术在高性能GPU服务器中的演进如下图所示:
 NVLink 1.0
连接方式:采用4通道连接。
总带宽:实现高达160 GB/s的双向总带宽。
用途:主要用于加速GPU之间的数据传输,提升协同计算性能。
NVLink 2.0
连接方式:基于6通道连接。
总带宽:将双向总带宽提升至300 GB/s。
性能提升:提供更高的数据传输速率,改善GPU间通信效率。
NVLink 3.0
连接方式:采用12通道连接。
总带宽:达到双向总带宽600 GB/s。
新增特性:引入新技术和协议,提高通信带宽和效率。
NVLink 4.0
连接方式:使用18通道连接。
总带宽:进一步增加至双向总带宽900 GB/s。
性能改进:通过增加通道数量,NVLink 4.0能更好地满足高性能计算应用对更大带宽的需求。
NVLink 1.0、2.0、3.0和4.0之间的关键区别主要在于连接通道数目的增加、所支持的总带宽以及由此带来的性能改进。随着版本迭代,NVLink不断优化GPU间的数据传输能力,以适应日益复杂且要求严苛的应用场景。
NVSwitch
NVSwitch是NVIDIA专为满足高性能计算应用需求而研发的一款交换芯片,其核心作用在于实现同一主机内部多颗GPU之间的高速、低延迟通信。
下图呈现了一台典型配置8块A100 GPU的主机硬件连接拓扑结构。
NVLink 1.0
连接方式:采用4通道连接。
总带宽:实现高达160 GB/s的双向总带宽。
用途:主要用于加速GPU之间的数据传输,提升协同计算性能。
NVLink 2.0
连接方式:基于6通道连接。
总带宽:将双向总带宽提升至300 GB/s。
性能提升:提供更高的数据传输速率,改善GPU间通信效率。
NVLink 3.0
连接方式:采用12通道连接。
总带宽:达到双向总带宽600 GB/s。
新增特性:引入新技术和协议,提高通信带宽和效率。
NVLink 4.0
连接方式:使用18通道连接。
总带宽:进一步增加至双向总带宽900 GB/s。
性能改进:通过增加通道数量,NVLink 4.0能更好地满足高性能计算应用对更大带宽的需求。
NVLink 1.0、2.0、3.0和4.0之间的关键区别主要在于连接通道数目的增加、所支持的总带宽以及由此带来的性能改进。随着版本迭代,NVLink不断优化GPU间的数据传输能力,以适应日益复杂且要求严苛的应用场景。
NVSwitch
NVSwitch是NVIDIA专为满足高性能计算应用需求而研发的一款交换芯片,其核心作用在于实现同一主机内部多颗GPU之间的高速、低延迟通信。
下图呈现了一台典型配置8块A100 GPU的主机硬件连接拓扑结构。
 下图展示的是浪潮NF5488A5 NVIDIA HGX A100 8 GPU组装侧视图。在该图中,我们可以清楚地看到,在右侧六个大型散热器下方隐蔽着一块NVSwitch芯片,它紧密围绕并服务于周围的八片A100 GPU,以确保GPU间的高效数据传输。
下图展示的是浪潮NF5488A5 NVIDIA HGX A100 8 GPU组装侧视图。在该图中,我们可以清楚地看到,在右侧六个大型散热器下方隐蔽着一块NVSwitch芯片,它紧密围绕并服务于周围的八片A100 GPU,以确保GPU间的高效数据传输。
 NVLink交换机
NVLink交换机是一种由NVIDIA专为在分布式计算环境中的不同主机间实现GPU设备间高性能通信而设计制造的独立交换设备。不同于集成于单个主机内部GPU模块上的NVSwitch,NVLink交换机旨在解决跨主机连接问题。可能有人会混淆NVLink交换机和NVSwitch的概念,但实际上早期提及的“NVLink交换机”是指安装在GPU模块上的切换芯片。直至2022年,NVIDIA将此芯片技术发展为一款独立型交换机产品,并正式命名为NVLink交换机。
HBM(高带宽内存)
传统上,GPU内存与常见的DDR(双倍数据速率)内存相似,通过物理插槽插入主板并通过PCIe接口与CPU或GPU进行连接。然而,这种配置在PCIe总线中造成了带宽瓶颈,其中Gen4版本提供64GB/s的带宽,Gen5版本则将其提升至128GB/s。
为了突破这一限制,包括但不限于NVIDIA在内的多家GPU制造商采取了创新手段,即将多个DDR芯片堆叠整合,形成了所谓的高带宽内存(HBM)。例如,在探讨H100时所展现的设计,GPU直接与其搭载的HBM内存相连,无需再经过PCIe交换芯片,从而极大地提高了数据传输速度,理论上可实现显著的数量级性能提升。因此,“高带宽内存”(HBM)这一术语精准地描述了这种先进的内存架构。
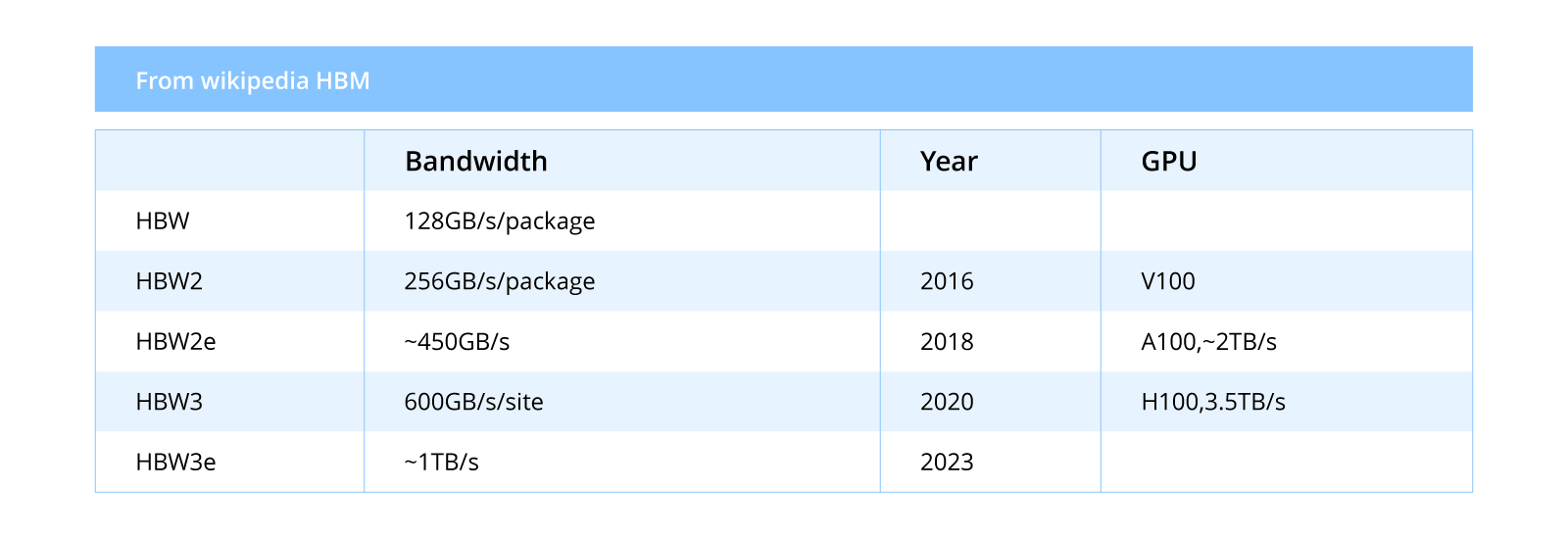
HBM的发展历程:从HBM1到HBM3e
NVLink交换机
NVLink交换机是一种由NVIDIA专为在分布式计算环境中的不同主机间实现GPU设备间高性能通信而设计制造的独立交换设备。不同于集成于单个主机内部GPU模块上的NVSwitch,NVLink交换机旨在解决跨主机连接问题。可能有人会混淆NVLink交换机和NVSwitch的概念,但实际上早期提及的“NVLink交换机”是指安装在GPU模块上的切换芯片。直至2022年,NVIDIA将此芯片技术发展为一款独立型交换机产品,并正式命名为NVLink交换机。
HBM(高带宽内存)
传统上,GPU内存与常见的DDR(双倍数据速率)内存相似,通过物理插槽插入主板并通过PCIe接口与CPU或GPU进行连接。然而,这种配置在PCIe总线中造成了带宽瓶颈,其中Gen4版本提供64GB/s的带宽,Gen5版本则将其提升至128GB/s。
为了突破这一限制,包括但不限于NVIDIA在内的多家GPU制造商采取了创新手段,即将多个DDR芯片堆叠整合,形成了所谓的高带宽内存(HBM)。例如,在探讨H100时所展现的设计,GPU直接与其搭载的HBM内存相连,无需再经过PCIe交换芯片,从而极大地提高了数据传输速度,理论上可实现显著的数量级性能提升。因此,“高带宽内存”(HBM)这一术语精准地描述了这种先进的内存架构。
HBM的发展历程:从HBM1到HBM3e
 带宽单位解析
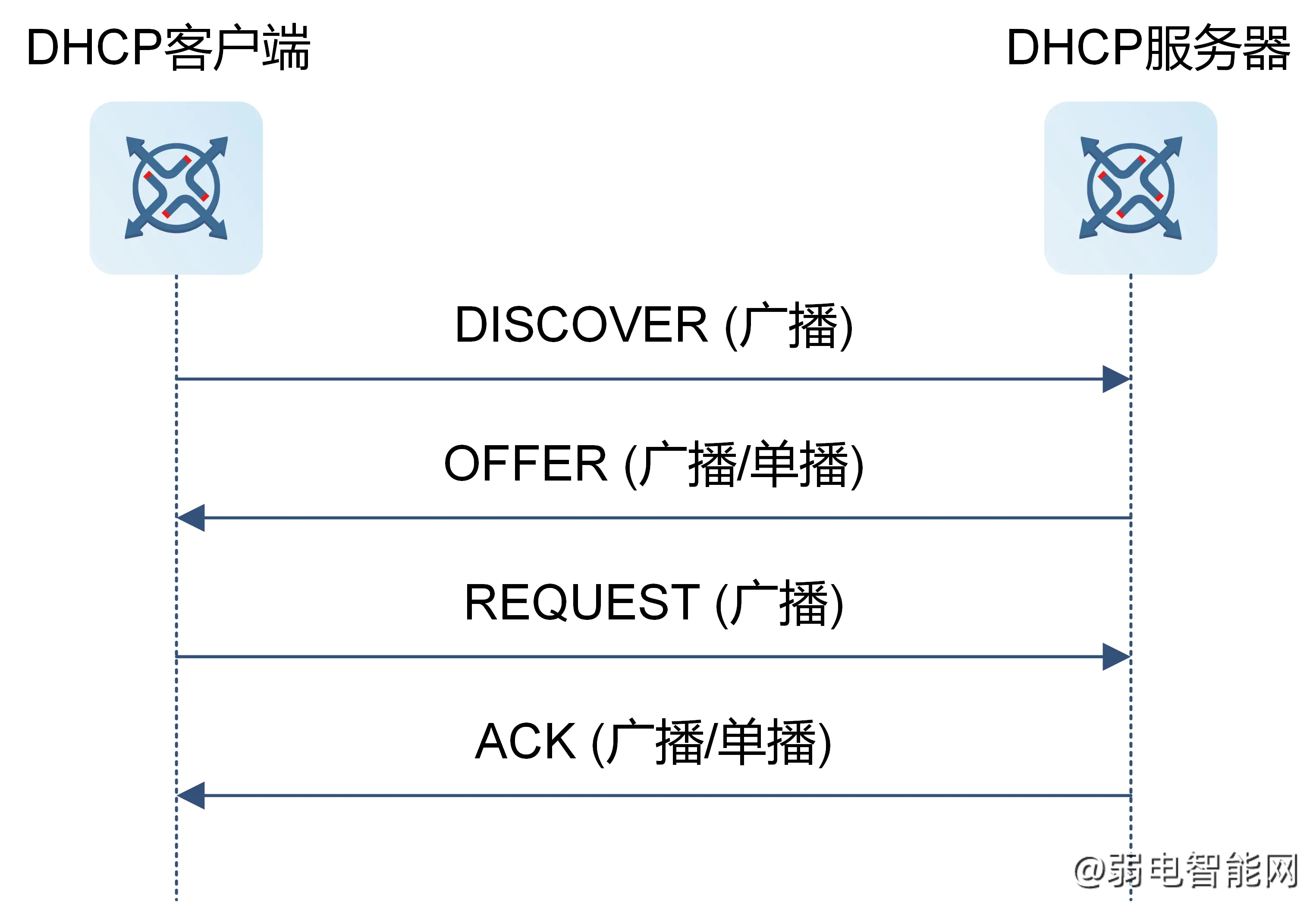
在大规模GPU计算训练领域,系统性能与数据传输速度密切相关,涉及到的关键通道包括PCIe带宽、内存带宽、NVLink带宽、HBM带宽以及网络带宽等。在衡量这些不同的数据传输速率时,需注意使用的带宽单位有所不同。
在网络通信场景下,数据速率通常以每秒比特数(bit/s)表示,且为了区分发送(TX)和接收(RX),常采用单向传输速率来衡量。而在诸如PCIe、内存、NVLink及HBM等其他硬件组件中,带宽指标则通常使用每秒字节数(Byte/s)或每秒事务数(T/s)来衡量,并且这些测量值一般代表双向总的带宽容量,涵盖了上行和下行两个方向的数据流。
因此,在比较评估不同组件之间的带宽时,准确识别并转换相应的带宽单位至关重要,这有助于我们全面理解影响大规模GPU训练性能的数据传输能力。汇鑫科服隶属于北京通忆汇鑫科技有限公司, 成立于2007年,是一家互联网+、物联网、人工智能、大数据技术应用公司,专注于楼宇提供智能化产品与服务。致力服务写字楼内发展中的中小企业 ,2009年首创楼宇通信BOO模式,以驻地网运营模式为楼宇提供配套运营服务;汇鑫科服始终以客户管理效率为导向,一站式 ICT服务平台,提升写字楼办公场景的办公效率和体验;
带宽单位解析
在大规模GPU计算训练领域,系统性能与数据传输速度密切相关,涉及到的关键通道包括PCIe带宽、内存带宽、NVLink带宽、HBM带宽以及网络带宽等。在衡量这些不同的数据传输速率时,需注意使用的带宽单位有所不同。
在网络通信场景下,数据速率通常以每秒比特数(bit/s)表示,且为了区分发送(TX)和接收(RX),常采用单向传输速率来衡量。而在诸如PCIe、内存、NVLink及HBM等其他硬件组件中,带宽指标则通常使用每秒字节数(Byte/s)或每秒事务数(T/s)来衡量,并且这些测量值一般代表双向总的带宽容量,涵盖了上行和下行两个方向的数据流。
因此,在比较评估不同组件之间的带宽时,准确识别并转换相应的带宽单位至关重要,这有助于我们全面理解影响大规模GPU训练性能的数据传输能力。汇鑫科服隶属于北京通忆汇鑫科技有限公司, 成立于2007年,是一家互联网+、物联网、人工智能、大数据技术应用公司,专注于楼宇提供智能化产品与服务。致力服务写字楼内发展中的中小企业 ,2009年首创楼宇通信BOO模式,以驻地网运营模式为楼宇提供配套运营服务;汇鑫科服始终以客户管理效率为导向,一站式 ICT服务平台,提升写字楼办公场景的办公效率和体验;