在多GPU系统中,CPU需要在不同GPU之间中转数据,这种通过PCIe或车载以太网进行的传输速度极低,严重限制了系统整体性能。例如,车载以太网的速度仅为千兆甚至百兆,而GPU内部带宽高达1000GB/s,这种巨大的差距就像是用小货车运输大量货物,效率极低。
为解决这一问题,英伟达推出了多项技术。2010年的GPU Direct shared memory减少了数据复制步骤,2011年的GPU Direct P2P则直接去掉了CPU中转环节。2014年发布的NVLink 1.0在P100 GPU之间实现了高速连接,带宽达到160GB/s,远超PCIe。2016年,IBM的Power 8服务器搭载英伟达GPU,使用NVLink实现了80GB/s的带宽,性能显著提升。
尽管第四代PCIe在2017年发布,但车载芯片大多仍停留在这一水平。相比之下,英伟达的下一代自动驾驶芯片将采用第五代PCIe,带宽高达31.5GB/s,远超车载以太网。然而,即便如此,与NVLINK的最新1800GB/s带宽相比,仍有巨大差距。
AMD和英特尔也在努力提升数据传输效率。AMD的Infinity Fabric技术支持高效的数据传输和内存共享,其最新的Instinct MI300X平台通过第四代Infinity Fabric实现了高达1.5TB HBM3容量。英特尔则依赖以太网络,其Gaudi AI芯片使用了高带宽以太网络链接。
为了打破英伟达在AI加速器领域的垄断,多家公司联合推出了UALink技术,旨在建立一个开放的互联标准,连接多达1024个GPU AI加速器,提升数据传输速度并降低延迟。
总的来说,尽管算力数值重要,但数据传输带宽同样关键。车载领域的复杂性要求更高的带宽和更高效的传输技术,才能真正实现自动驾驶的高性能计算需求。
首先我们要了解汽车自动驾驶乃至所有AI运算的基本流程,可以简单理解为CPU负责下达命令,GPU负责计算。此过程可概括为:CPU根据任务类型分配任务,CPU看到大规模并行运算任务,就启动GPU,对GPU发号施令,GPU从显存或共享存储器(车载一般是LPDDR4或LPDDR5)读取模型全部参数,由于GPU或CPU的缓存通常只有几MB甚至是KB,所以模型参数始终都在显存或LPDDR里,每一次推理运算都要重新读出,GPU计算完成,再将数据传输给CPU。

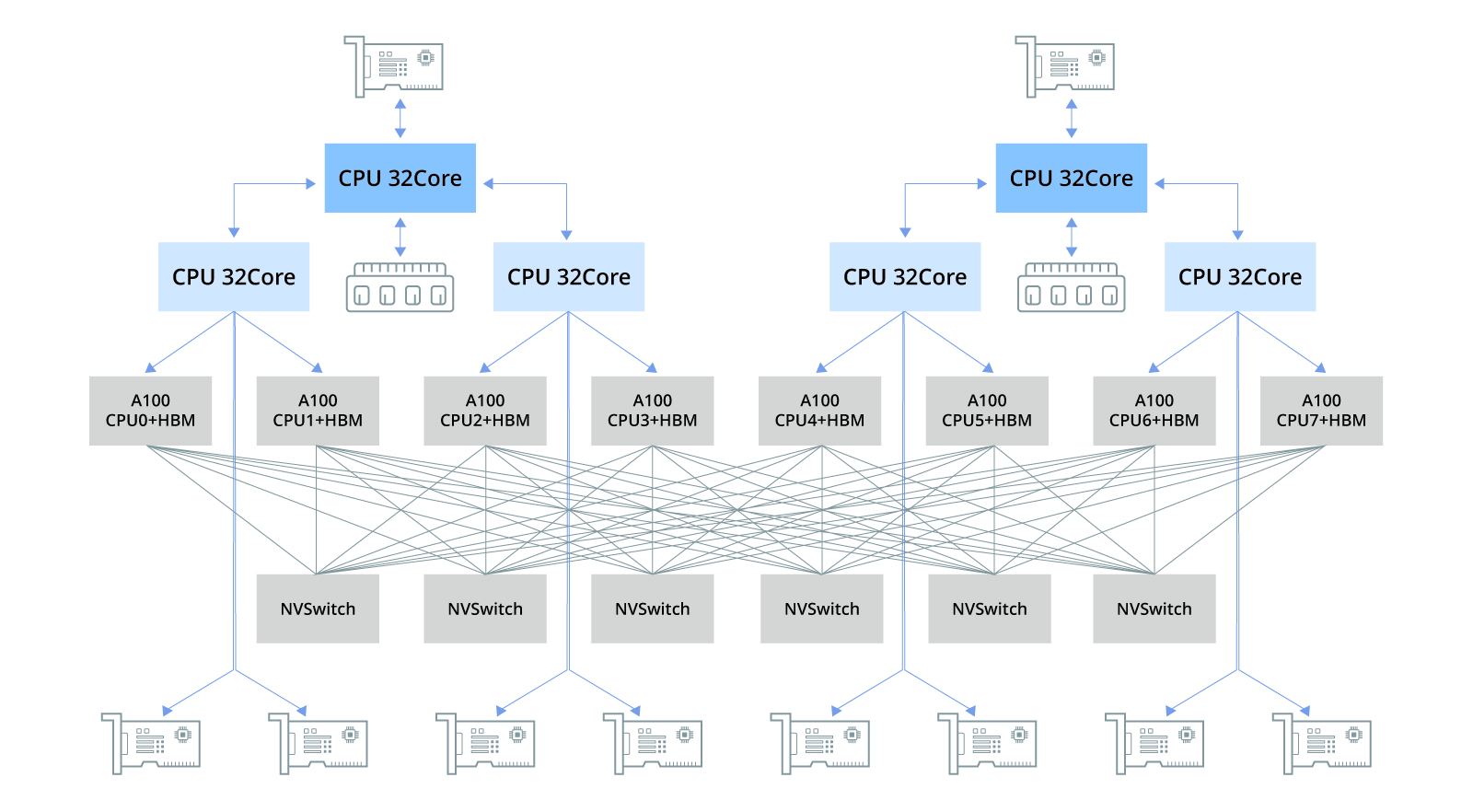
如果有多个GPU,那么由CPU分配任务,GPU与GPU之间的数据传递还是需要通过CPU中转,CPU会从其中一个GPU中先拷贝数据,再中转给其他GPU,效率非常低下,因为CPU与GPU之间一般是PCIe通讯,而车载领域为了节约成本,一般是千兆甚至百兆以太网,这个传输速率非常低下,是一个严重的瓶颈。GPU内部的带宽至少是1000GB/s的,而千兆车载以太网是0.125GB/s,这就好比一个工厂,每天能出产1万吨货物,其中100吨要运输,而这家工厂只有一辆每次1.25吨的车辆来装载货物,还需要一个物流中心中转,这样即使这样的工厂有10家,产能也不是10万吨,而是2.5吨。同理,即使10个Orin用千兆以太网连接,算力也不会到400TOPS。
GPU之间数据传递
英伟达早在20年前就意识到了这个瓶颈,逐步来解决这个问题。
2010年,英伟达推出GPU Direct shared memory技术,通过减少一次复制的步骤,加快了GPU1-CPU-GPU2的数据传输速度。
2011年,英伟达又推出GPU Direct P2P技术,直接去掉了数据在CPU中转的步骤,进一步加快传输速度。
2014年,NVLink 1.0发布并在P100 GPU芯片之间实现,两个GPU之间有四个NVLink,每个链路由八个信道组成,每个信道的速度为20Gb/s,系统整体双向带宽为160GB/s(20*8*4*2)/8=160GB/s),是PCle3x16的五倍。
2016年9月,IBM发布Power 8服务器新版本,搭载英伟达GPU,两颗Power 8 CPU连接了4颗英伟达P100 GPU,其中数据传输的纽带从PCIe换成了英伟达自研NVLink,带宽高达80GB/s,通信速度提高了5倍,性能提升了14%。
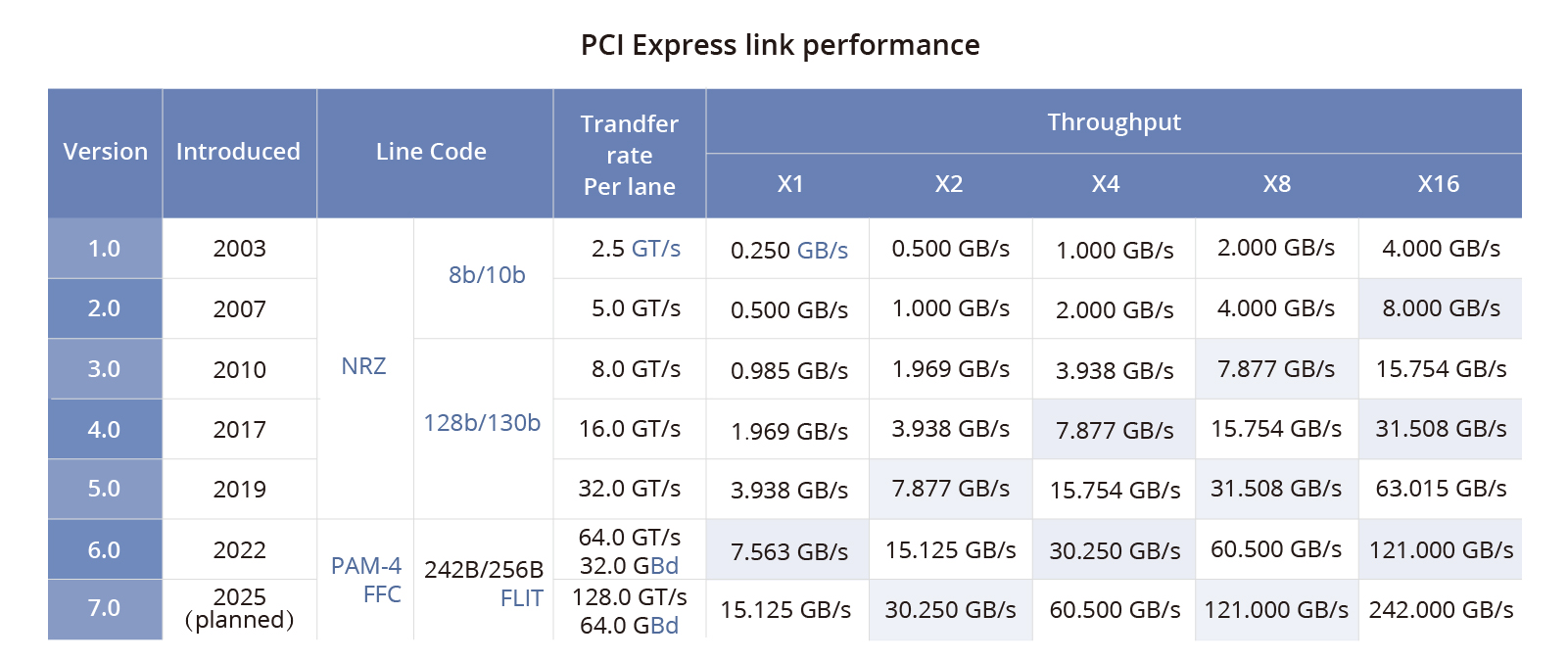
PCIe的各版本参数
车载芯片目前使用的顶多是第四代PCIe,实际第四代PCIe标准早在2011年就确定了,但考虑到这可能导致第三代产品生命周期太短,因此直到2017年才正式发布,英伟达下一代自动驾驶芯片才是第五代PCIe,Orin是第四代,并且目前市面上还没有基于PCIe交换机的Orin系统,所有厂家都是为了节约成本,使用千兆车载以太网,最多万兆,即1.25GB/s,Orin如果用PCIe交换机系统,带宽是31.5GB/s,远超车载以太网,但和NVLINK最新的1800GB/s带宽比差距极大。
严格讲,即使用1800GB/s的NVLINK连接,两张显卡算力也有通讯损耗,也不是简单的算力翻倍,只是损耗很低而已。而车载领域的千兆以太网,笔者认为损耗至少也有80%。国内也有厂家开始考虑用PCIe交换机连接两个Orin,好在第四代PCIe交换机的研发成本早就被分摊完毕了,目前车载PCIe交换机只有Microchip一家提供,价格也不算高,不过比车载以太网交换机还是要贵几十美元。
车载PCIe交换机连接
Orin当然没有NVLink接口,连独立的显存也没有。
NVLINK每代参数
NVLink是全封闭生态,不像PCIe需要挤牙膏式发展,基本上每两年升级一次,相对PCIe,NVLINK遥遥领先,2017年的NVLink比2025年的PCIe都强不少。然而,也不能全怪PCIe太慢,PCIe要考虑成本,也考虑使用场合,而NVLink只需要考虑AI计算场合。
从第二代NVLink开始,英伟达开发了NVLink Switch芯片,这让英伟达垄断了AI芯片,单芯片或者说单卡。实际,英伟达并不比AMD或英特尔强,比如AMD的MI300X比英伟达的H100性能高出很多,价格也低很多,之所以卖不过H100,CUDA并非是关键因素。
从上图可以看出,PyTorch 1.8起,就原生支持AMD的ROCm,可以方便地在原生环境下运行,不用去配置docker了。
关键就是NVLink与NVLink Switch。
历代NVLink Switch
NVLink组成局域网连接多张H100显卡构成一个节点,再用NVLink Switch将这些连接成更大的计算规模,DGX H100目前最高双向带宽高达3.6TB/s。
在更高层级上,英伟达也有宽广的护城河,英伟达2019年3月发起对Mellanox的收购 ,并且于2020年4月完成收购 ,经过这次收购NVIDIA获取了InfiniBand、Ethernet、SmartNIC、DPU及LinkX互联的能力。
英伟达的网络布局
英伟达就是一个三头怪兽,CUDA和GPU这两个头还好对付,网络这个头,差距太大。
与英伟达的NVLink相似,AMD则推出了其Infinity Fabric技术,支持芯片间、芯片对芯片,以及即将推出的节点对节点的数据传输,不过其最初是应对CPU到GPU的统一存储的,而非多张显卡通讯,因此它基本沿用了PCIe标准。Infinity Fabric是AMD在其「Zen」微架构中引入的关键特性,旨在提高整体系统效能,特别是在多核心处理器和数据中心环境中。
Infinity Fabric由两部分组成:数据布线(Data Fabric)和控制布线(Control Fabric)。数据布线用于处理器内部和处理器之间的数据传输,而控制布线则负责处理器的功耗、频率和安全性等方面的管理。
Infinity Fabric的主要特点包括:
1)高效率:Infinity Fabric设计用于提供高效率的数据传输,支持多个装置之间的高速通讯;
2)模块化:Infinity Fabric支持AMD的小芯片(chiplet)架构,允许不同功能的芯片模块透过高速互连进行组合;
3)内存共享:Infinity Fabric支持CPU和GPU之间的内存共享,有助于提高异构运算的效率;
4)扩展性:Infinity Fabric的设计允许它随着技术进步和需求成长而扩展。
AMD最新的AI加速器Instinct MI300X 平台,就通过第四代AMD Infinity Fabric连结将8 个完全连接的MI300X GPU OAM 模块整合到业界标准OCP 设计中,为低延迟AI 处理提供高达1.5TB HBM3容量。第四代Infinity Fabric支持每通道高达32Gbps,每连结产生128GB/s 的双向带宽。但仅限于8个,再多就需要加入外部互联。
不同于NVLink仅限于内部使用,AMD已开始向新合作伙伴开放其Infinity Fabric 生态系统。在2025年年底AMD MI3000的发布会上,Broadcom宣布其下一代PCIe交换器将支持XGMI/Infinity Fabric。不仅如此,AMD还希望Arista、博通、Cisco等合作伙伴能推出适用于Infinity Fabric 等产品的交换机,能够方便MI3000在单一系统外实现芯片间通讯。这类似于英伟达的NVSwitch。
英特尔是以太网络的坚实拥护者,没办法,英特尔在计算集群网络上几乎没有布局,只能依靠最传统的以太网络。英特尔的用于生成式AI的Gaudi AI芯片则一直沿用传统的以太网络互联技术。Gaudi 2 每个芯片使用了24 个100Gb以太网络链接;Gaudi 3也使用了24 个200 Gbps 以太网络RDMA NIC,但它们将这些连结的带宽增加了一倍,达到200Gb/秒,这与NVLINK还相差很多。
2024年3月,AMD、博通、思科、Google、惠普、英特尔、Meta和微软在内的八家公司宣告,为人工智能数据中心的网络制定了新的互联技术UALink(Ultra Accelerator Link)。通过为AI加速器之间的通信建立一个开放标准,以挑战英伟达在AI加速器一家独大的地位。据消息披露,UALink提议的第一个标准版本UALink 1.0,将连接多达1024个GPU AI加速器,组成一个计算“集群”,共同完成大规模计算任务。根据UALink推广组的说法,基于包括AMD的Infinity Fabric在内的“开放标准”,UALink 1.0将允许AI加速器所附带的内存之间的直接加载和存储,并且与现有互连规范相比,总体上将提高速度,同时降低数据传输延迟。
实际即使算力数值相同,实际计算也会是天壤之别,英伟达A100的INT8算力是1248TOPS,国内售价20-25万人民币,英伟达RTX4090的INT8算力是1320TOPS,售价是1.3万人民币,两者显然差距巨大,存储带宽比算力更重要,车载领域远比服务器领域复杂,它是共享存储,至于带宽,很少人研究过。
NVLink的持续演进也证明了显卡算力不会简单叠加,要不然就没必要持续升级NVLink,至于带宽不及第五代NVLink万分之一的车载以太网,两个Orin叠加,结果可想而知。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。