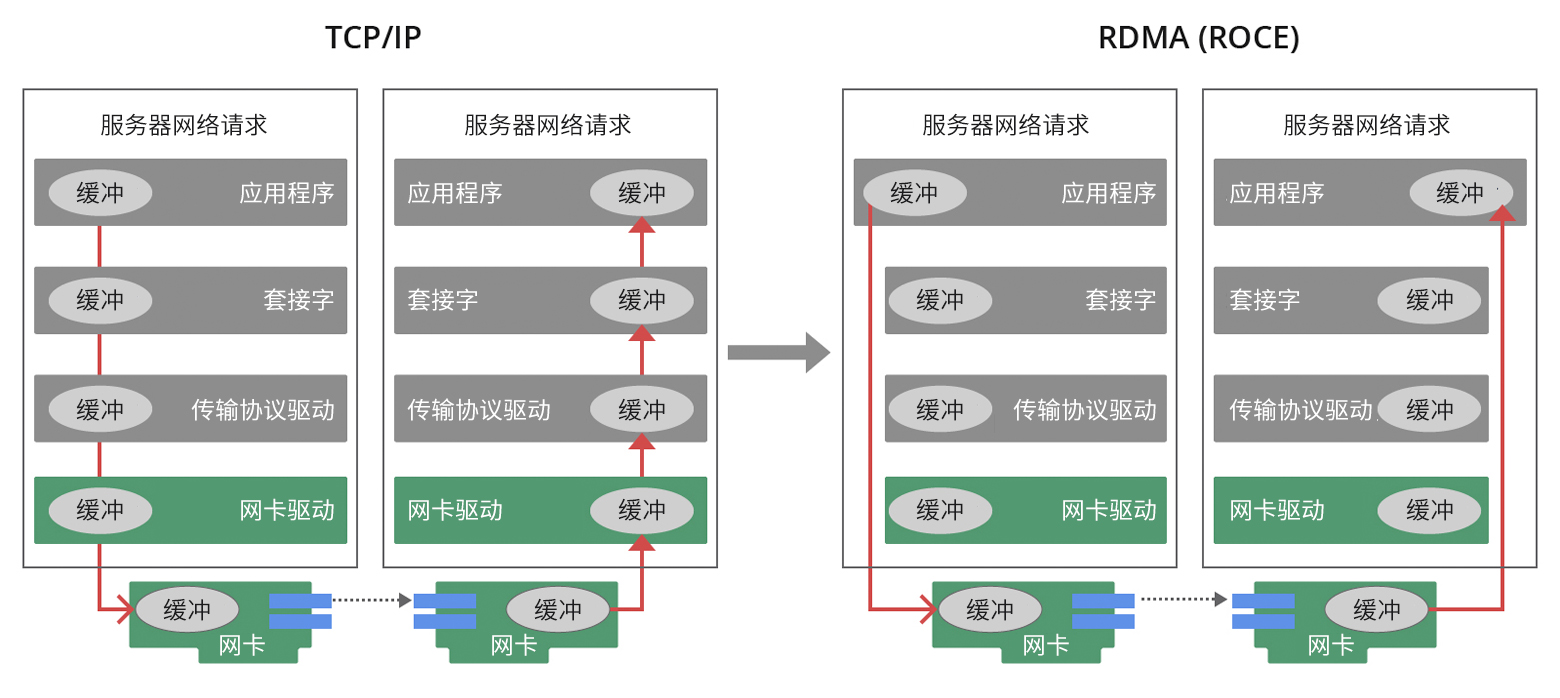
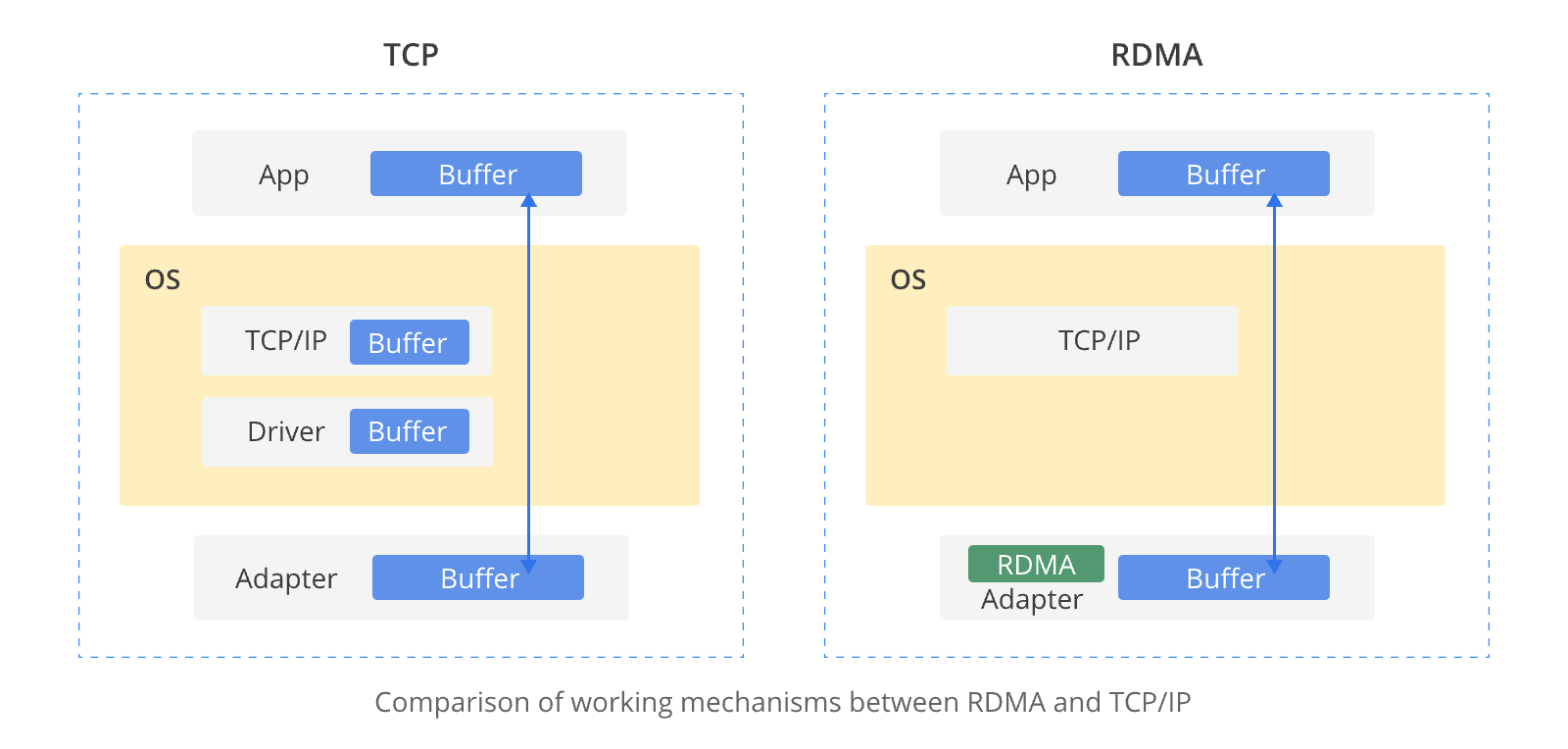
RDMA技术的核心优势在于绕过操作系统内核,实现网络间的直接内存访问,大幅减少CPU开销和延迟。具体而言,RDMA通过内核绕行和零拷贝技术,降低了网络传输延迟,减少了CPU使用率,缓解了内存带宽瓶颈,提升了带宽资源利用效率。应用程序可以直接访问远程虚拟内存空间,消除了数据在不同层级缓冲区之间复制的开销,确保计算计算节点以更高速度、更低延迟进行高效数据交互。
在RDMA技术的应用中,GPU Direct-RDMA技术尤为亮眼。传统的TCP网络架构在数据包管理上高度依赖CPU处理,难以充分利用带宽资源。而GPU Direct-RDMA技术实现了跨多台服务器和GPU集群内不同GPU之间的直接数据交互,显著提升了HPC系统性能。尤其在深度学习模型复杂度增加和数据规模增长的背景下,多台机器和多个GPU并行协同工作的分布式训练方式变得不可或缺,GPU Direct-RDMA技术大幅提升了通信速度,推动了整个集群系统的性能提升。
此外,RDMA网络中的ECN(显式拥塞通知)和PFC(基于优先级的流量控制)技术也发挥了重要作用。ECN通过IP数据报头中的DS字段实时反映网络拥塞状况,终端设备据此调整传输策略,缓解拥塞压力。PFC则提供了逐跳优先级流控能力,确保某一类型流量出现拥塞时,不影响其他类型流量的正常转发。
在RDMA和RoCE产品的选择上,英伟达等厂商基于丰富经验,将ECN视为关键的拥塞控制手段,并整合ETS机制和物理缓存优化技术,实现精细化资源调度。然而,PFC技术虽有一定优势,但其潜在的网络死锁风险不容忽视。
总之,RDMA技术通过内核绕行、零拷贝、ECN和PFC等多种机制,有效提升了数据传输效率和系统性能,成为现代数据中心不可或缺的关键技术。随着企业数字化进程的加速推进,各类创新应用不断涌现并逐步落实。数据作为现代企业的核心资产,对高性能计算、大数据深度分析以及多元存储解决方案的需求日益增长。然而,在满足这些新兴应用场景时,传统的TCP/UDP等数据传输协议在性能和效率上面临重大挑战,出现了许多技术瓶颈。 为应对这一问题,RDMA(远程直接内存访问)技术应运而生,逐渐成为提升集群性能的关键手段。RDMA通过绕过操作系统内核,实现网络间的直接内存访问,大幅减少数据处理中的CPU开销和延迟,从而有效解决了传统协议在高吞吐量和低延迟场景下的不足。借助RDMA技术,数据中心能够有效优化集群间的数据交互效率,进而促进高性能计算任务、大规模数据分析及HPC应用整体效能的显著提升。本文将深入探索RDMA技术,并帮助您选择合适的相关产品。 RDMA技术的工作原理 与传统的TCP/IP通信机制相比较,RDMA技术通过运用内核绕行和零拷贝技术实现了关键性能优化。这种优化显著降低了网络传输延迟,并有效减少了CPU使用率,进而缓解了内存带宽瓶颈问题,实现系统对带宽资源利用效率的提升。 具体而言,RDMA技术开创了一种基于I/O直接访问的新型通道模式。在此模式下,应用程序能够直接借助RDMA设备的能力,跨越操作系统内核的限制,实现对远程虚拟内存空间的直接读写。这一特性有效消除了数据在不同层级缓冲区之间复制的开销,以及上下文切换带来的延迟,从而确保集群中的计算节点能够以更高速度、更低延迟进行高效的数据交互,有力地提升了整个集群系统的性能表现。
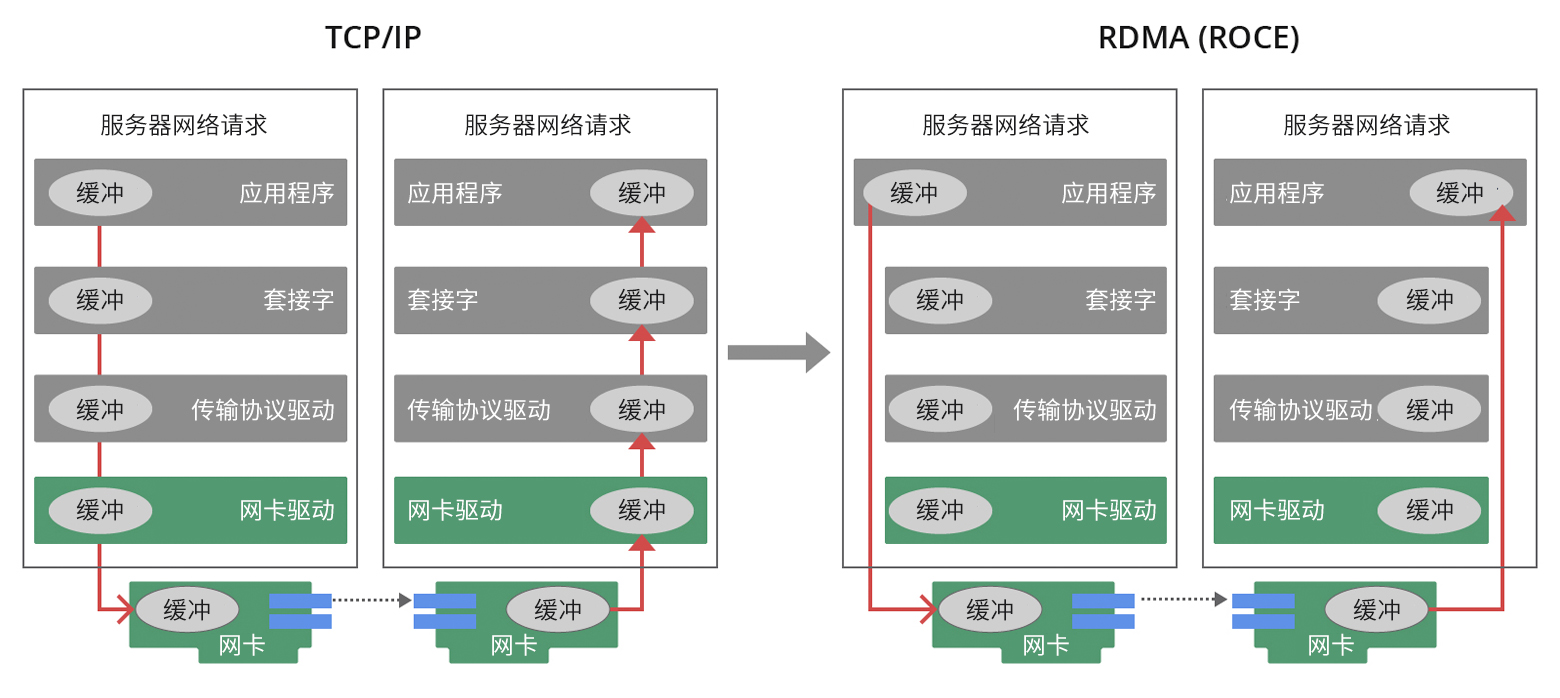 RDMA技术在应用程序与网络架构之间构建了一条专门的数据传输通路,直接绕过了操作系统内核层的处理环节。通过优化这条直连数据链路,有效降低用于数据转发的CPU资源占用率,充分利用ASIC芯片提供的强大计算性能。RDMA凭借其独特的机制,能够在不干扰操作系统的情况下,高效地将数据直接从网络传输至计算机存储区域,并实现不同系统内存间的高速数据迁移。 这一策略有效地消除了传统外部内存复制和上下报文切换过程中产生的额外开销,从而释放宝贵的内存带宽资源和CPU周期,大幅提升应用系统的运行效率及整个集群的综合效能。 目前,RDMA技术已在全球范围内的超级计算中心及互联网企业中得到广泛应用,并成功建立了一个成熟的应用程序与网络设备协同工作的生态系统。在当前项目中,将RDMA技术整合进企业级大规模数据中心体系结构,标志着该技术生态迈入了一个崭新的发展阶段。
RDMA技术发展
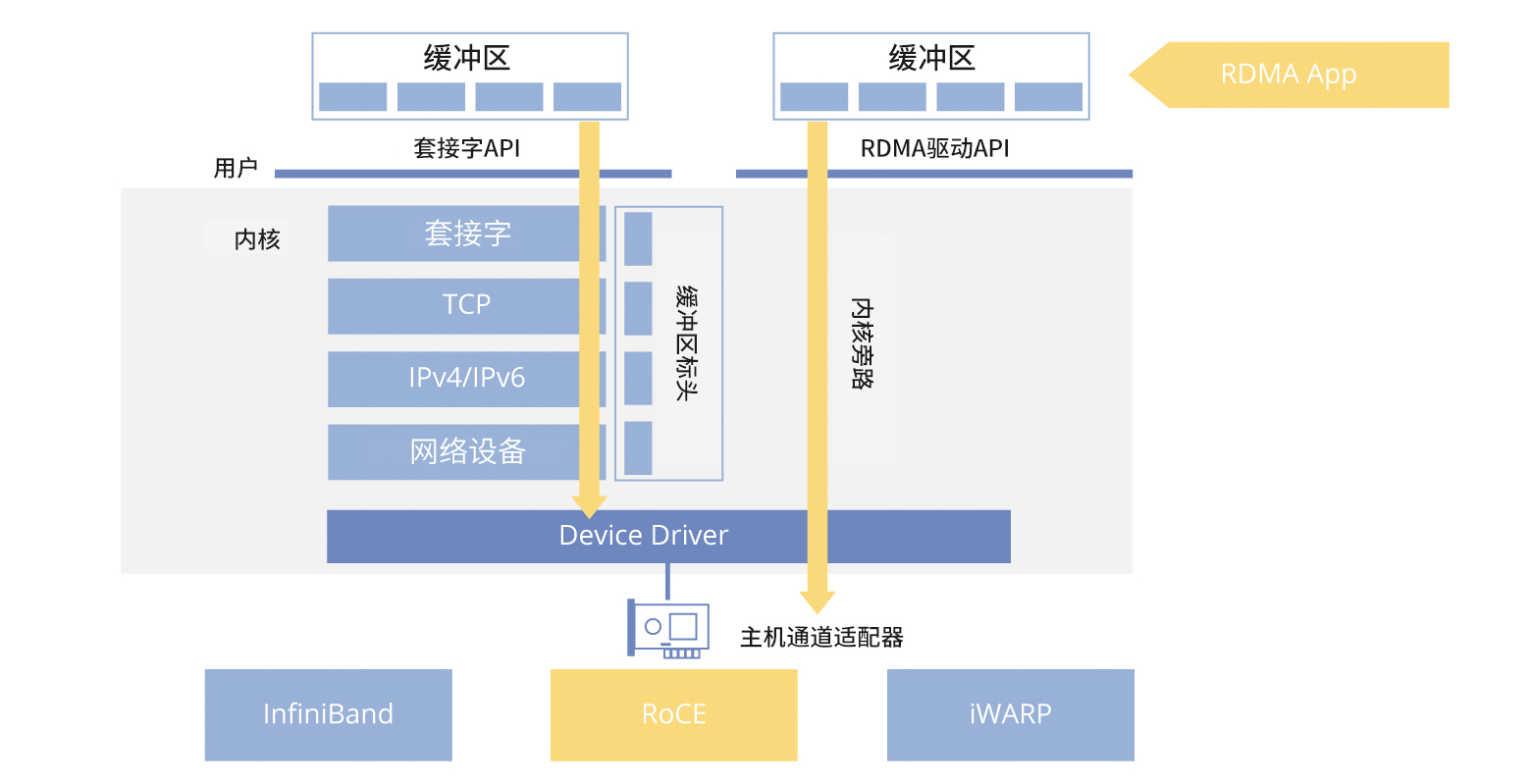
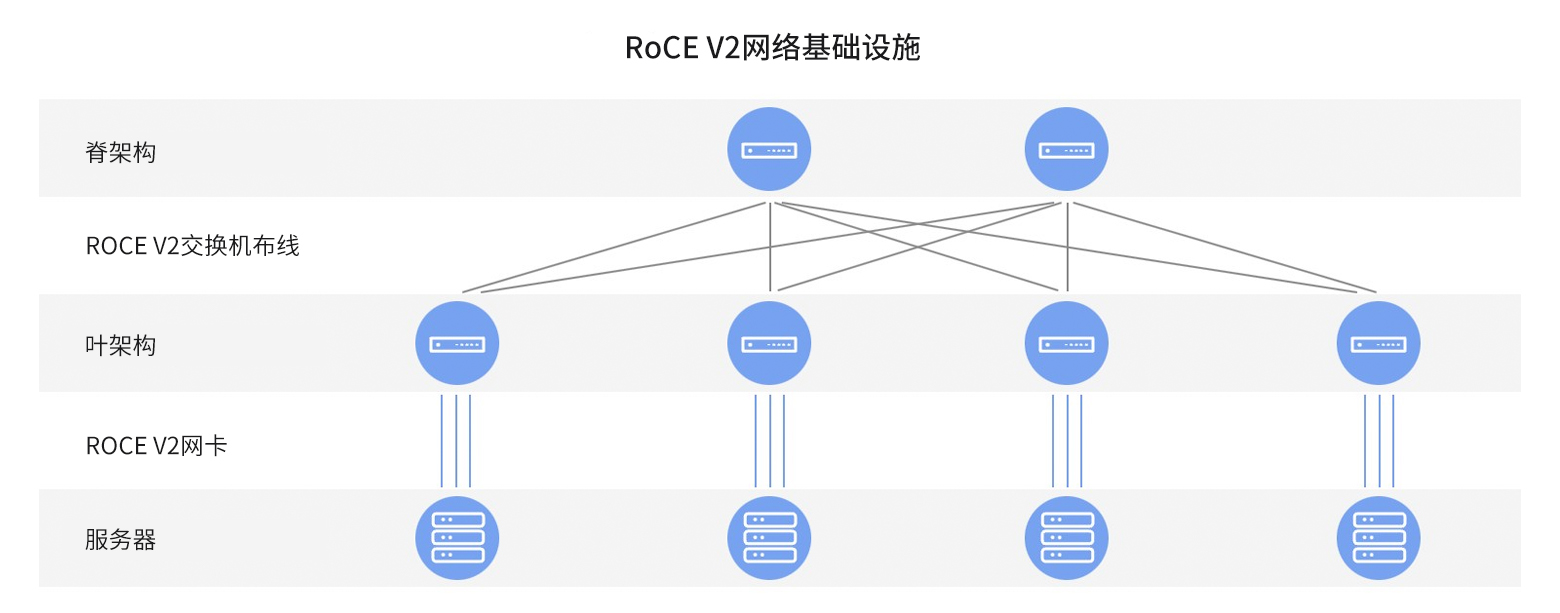
作为一种前沿的高性能网络通信技术,RDMA(远程直接内存访问)是InfiniBand标准的核心支撑。其原理基于DMA(直接内存访问),即允许设备在无需CPU介入的情况下直接访问主机内存资源。而RDMA更进一步,通过在网络接口层面实现跨越网络的直接内存数据交互,绕过操作系统内核处理环节,从而提供高效、低延迟且高吞吐量的数据传输服务,尤其适用于大规模并行计算集群环境。 RDMA技术使得应用程序能够更有效地管理和利用网络链路资源,实现传输效率优化和网卡功能的充分利用。最初专为InfiniBand网络设计实施的RDMA技术,随着需求增长逐渐扩展至传统的以太网领域。在此基础上诞生了两种基于以太网的RDMA实现方式:iWARP和RoCE,其中RoCE又细分出RoCEv1和RoCEv2两个版本。 相较于成本相对较高的InfiniBand方案,RoCE与iWARP技术提供了更具经济效益的硬件解决方案。RoCE技术以其显著优势及生态系统的发展,对集群性能提升起到了关键作用。 当RDMA技术运行于以太网环境中时,我们称之为RoCE。目前,基于RoCE v2协议的解决方案在高性能网络领域得到了广泛应用。该协议成功将以太网与RDMA技术相结合,在多种以太网部署场景中实现了广泛应用和深入推广,有效推动了集群性能的整体跃升。
RDMA技术在应用程序与网络架构之间构建了一条专门的数据传输通路,直接绕过了操作系统内核层的处理环节。通过优化这条直连数据链路,有效降低用于数据转发的CPU资源占用率,充分利用ASIC芯片提供的强大计算性能。RDMA凭借其独特的机制,能够在不干扰操作系统的情况下,高效地将数据直接从网络传输至计算机存储区域,并实现不同系统内存间的高速数据迁移。 这一策略有效地消除了传统外部内存复制和上下报文切换过程中产生的额外开销,从而释放宝贵的内存带宽资源和CPU周期,大幅提升应用系统的运行效率及整个集群的综合效能。 目前,RDMA技术已在全球范围内的超级计算中心及互联网企业中得到广泛应用,并成功建立了一个成熟的应用程序与网络设备协同工作的生态系统。在当前项目中,将RDMA技术整合进企业级大规模数据中心体系结构,标志着该技术生态迈入了一个崭新的发展阶段。
RDMA技术发展
作为一种前沿的高性能网络通信技术,RDMA(远程直接内存访问)是InfiniBand标准的核心支撑。其原理基于DMA(直接内存访问),即允许设备在无需CPU介入的情况下直接访问主机内存资源。而RDMA更进一步,通过在网络接口层面实现跨越网络的直接内存数据交互,绕过操作系统内核处理环节,从而提供高效、低延迟且高吞吐量的数据传输服务,尤其适用于大规模并行计算集群环境。 RDMA技术使得应用程序能够更有效地管理和利用网络链路资源,实现传输效率优化和网卡功能的充分利用。最初专为InfiniBand网络设计实施的RDMA技术,随着需求增长逐渐扩展至传统的以太网领域。在此基础上诞生了两种基于以太网的RDMA实现方式:iWARP和RoCE,其中RoCE又细分出RoCEv1和RoCEv2两个版本。 相较于成本相对较高的InfiniBand方案,RoCE与iWARP技术提供了更具经济效益的硬件解决方案。RoCE技术以其显著优势及生态系统的发展,对集群性能提升起到了关键作用。 当RDMA技术运行于以太网环境中时,我们称之为RoCE。目前,基于RoCE v2协议的解决方案在高性能网络领域得到了广泛应用。该协议成功将以太网与RDMA技术相结合,在多种以太网部署场景中实现了广泛应用和深入推广,有效推动了集群性能的整体跃升。
 GPU Direct-RDMA技术提升HPC应用效率
在HPC应用性能优化的进程中,GPU Direct-RDMA技术至关重要。传统的TCP网络架构在数据包管理上高度依赖CPU处理,导致其难以充分利用现有的带宽资源,尤其是在对带宽和延迟要求较高的环境以及大规模集群训练场景中。 RDMA技术不仅革新了CPU内存中用户空间数据在网络中的高效传输,还实现了跨多台服务器和GPU集群内不同GPU之间的直接数据交互。该技术不仅提升了HPC系统性能,还为高性能计算领域带来了创新变化。 随着深度学习模型复杂度的增加及计算数据规模的指数级增长,单台机器的计算能力已无法满足日益严苛的需求。因此,多台机器和多个GPU并行协同工作的分布式训练方式变得不可或缺。在此情境下,各机器间的通信效率成为衡量分布式训练性能的关键指标。GPUDirect RDMA技术通过提供跨机器的GPU直接通信的能力,大幅提升了通信速度,从而有效推动整个集群系统的性能提升。
GPU Direct RDMA技术的定义及工作原理
GPU Direct RDMA是一项利用网卡RoCE功能的技术,其主要优势在于能够实现GPU集群内的服务器节点之间的高速内存数据交换。在网络设计与实施方面,英伟达(NVIDIA)通过支持GPU Direct RDMA功能大幅提升了GPU集群的性能。 在GPU集群网络领域,网络的低延迟和高带宽尤为重要。传统的网络传输方式有时会限制GPU的并行处理能力,导致资源利用率低下。特别是在多节点的GPU通信过程中,传统的高带宽数据传输链路通常需要经过CPU内存,这为内存读写操作和CPU负载带来了瓶颈问题。
GPU Direct-RDMA技术提升HPC应用效率
在HPC应用性能优化的进程中,GPU Direct-RDMA技术至关重要。传统的TCP网络架构在数据包管理上高度依赖CPU处理,导致其难以充分利用现有的带宽资源,尤其是在对带宽和延迟要求较高的环境以及大规模集群训练场景中。 RDMA技术不仅革新了CPU内存中用户空间数据在网络中的高效传输,还实现了跨多台服务器和GPU集群内不同GPU之间的直接数据交互。该技术不仅提升了HPC系统性能,还为高性能计算领域带来了创新变化。 随着深度学习模型复杂度的增加及计算数据规模的指数级增长,单台机器的计算能力已无法满足日益严苛的需求。因此,多台机器和多个GPU并行协同工作的分布式训练方式变得不可或缺。在此情境下,各机器间的通信效率成为衡量分布式训练性能的关键指标。GPUDirect RDMA技术通过提供跨机器的GPU直接通信的能力,大幅提升了通信速度,从而有效推动整个集群系统的性能提升。
GPU Direct RDMA技术的定义及工作原理
GPU Direct RDMA是一项利用网卡RoCE功能的技术,其主要优势在于能够实现GPU集群内的服务器节点之间的高速内存数据交换。在网络设计与实施方面,英伟达(NVIDIA)通过支持GPU Direct RDMA功能大幅提升了GPU集群的性能。 在GPU集群网络领域,网络的低延迟和高带宽尤为重要。传统的网络传输方式有时会限制GPU的并行处理能力,导致资源利用率低下。特别是在多节点的GPU通信过程中,传统的高带宽数据传输链路通常需要经过CPU内存,这为内存读写操作和CPU负载带来了瓶颈问题。
 为了解决这些问题,GPU Direct RDMA技术采用了一种直接的方法,使网卡设备能够直接与GPU连接,从而实现GPU内存空间之间的直接远程访问。这一创新显著提升了带宽和延迟性能,大幅提高了GPU集群运行效率。通过将网卡与GPU直接关联,GPU Direct RDMA消除了传统传输链路中涉及CPU的瓶颈,使得GPU之间的数据传输更为高效和迅速。
RDMA网络中的ECN与PFC技术
为了解决这些问题,GPU Direct RDMA技术采用了一种直接的方法,使网卡设备能够直接与GPU连接,从而实现GPU内存空间之间的直接远程访问。这一创新显著提升了带宽和延迟性能,大幅提高了GPU集群运行效率。通过将网卡与GPU直接关联,GPU Direct RDMA消除了传统传输链路中涉及CPU的瓶颈,使得GPU之间的数据传输更为高效和迅速。
RDMA网络中的ECN与PFC技术
 ECN(显式拥塞通知)技术
ECN在IP层与传输层引入了流量控制和端到端拥塞检测机制。该技术利用IP数据报头中的DS字段来实时反映网络传输链路上的拥塞状况。具备ECN功能的终端设备能够依据数据包内容动态评估网络拥塞状态,并据此调整传输策略以缓解拥塞压力。 增强型Fast ECN技术则通过在数据包出队列时即时标记ECN字段,显著减少了转发过程中ECN标记产生的延迟。这样,接收服务器能够快速识别并响应带有ECN标记的数据包,从而加快发射速率的动态调整过程。
PFC(基于优先级的流量控制)技术
PFC提供了逐跳优先级流控能力。当设备进行数据包转发时,会根据数据包的优先级实施调度与传输,并将数据包映射到相应的队列中。若某一优先级的数据包发射速率超过接收端的处理能力,导致接收端可用数据缓冲空间不足,此时设备将会向其前一跳节点发送PFC PAUSE帧。 收到PAUSE帧后,前一跳节点会暂停对应优先级数据包的传输,直至接收到PFC XON帧或等待一定老化时间后再恢复数据流量。通过这种方式,PFC确保了一种类型流量出现拥塞时,不会影响其他类型流量的正常转发,实现同一条链路上不同类型数据包之间互不干扰的顺畅运行。
RDMA优化和RoCE产品选择
在RDMA和RoCE产品优化选择上,英伟达(NVIDIA)基于其在无损以太网实践中的丰富经验,将ECN视为关键的拥塞控制手段。借助硬件加速的Fast ECN支持,系统能够实现快速响应并确保高效的流量管控。同时,通过整合ETS(增强型传输选择)机制和创新的物理缓存优化技术,资源调度得到了针对多元流量模型的精细化调整。 然而,尽管PFC(基于优先级的流量控制)技术带来了一定优势,但其潜在的网络死锁风险也不容忽视。对比分析表明,PFC流控机制在提高网络稳定性和解决由拥塞引发的丢包问题方面效果有限,并暴露出其固有的安全隐患与性能瓶颈。 RDMA专注于大幅提升远程数据传输速率,在实现端到端网络通信中扮演着核心角色。这一过程涵盖了主机侧内核绕过技术、网络卡上的传输层卸载处理,以及在网络侧实施拥塞流控制等复杂环节的深度融合。这些措施共同带来了显著的低延迟、高吞吐量特性,以及低CPU占用率等优势。 然而,当前RDMA的实际应用仍面临可扩展性受限和配置修改过程复杂性等挑战。因此,在不断演进的RDMA与RoCE产品领域中,精准把握技术发展趋势,充分应对各种局限性,是确保无缝集成及保持高性能网络解决方案长期稳定运行的关键。
飞速(FS)如何提供帮助
在构建能够显著提升集群性能的RDMA网络架构时,除了不可或缺的高性能RDMA适配器和强大计算能力的服务器之外,高速光模块、高性能交换机以及高质量线缆等核心组件同样至关重要。 作为专业的信息通信技术产品及解决方案提供商,
飞速(FS)
提供
高性能的交换机
、高速率光模块以及
集成智能技术的网卡
等,帮助企业构建和优化服务平台,以确保高效稳定的服务。 在搭建高性能网络系统的过程中,飞速(FS)凭借其独特优势,在经济效益与运行效能之间实现了理想平衡,成为众多企业部署此类网络时首选的合作伙伴。汇鑫科服隶属于北京通忆汇鑫科技有限公司, 成立于2007年,是一家互联网+、物联网、人工智能、大数据技术应用公司,专注于楼宇提供智能化产品与服务。致力服务写字楼内发展中的中小企业 ,2009年首创楼宇通信BOO模式,以驻地网运营模式为楼宇提供配套运营服务;汇鑫科服始终以客户管理效率为导向,一站式 ICT服务平台,提升写字楼办公场景的办公效率和体验;
ECN(显式拥塞通知)技术
ECN在IP层与传输层引入了流量控制和端到端拥塞检测机制。该技术利用IP数据报头中的DS字段来实时反映网络传输链路上的拥塞状况。具备ECN功能的终端设备能够依据数据包内容动态评估网络拥塞状态,并据此调整传输策略以缓解拥塞压力。 增强型Fast ECN技术则通过在数据包出队列时即时标记ECN字段,显著减少了转发过程中ECN标记产生的延迟。这样,接收服务器能够快速识别并响应带有ECN标记的数据包,从而加快发射速率的动态调整过程。
PFC(基于优先级的流量控制)技术
PFC提供了逐跳优先级流控能力。当设备进行数据包转发时,会根据数据包的优先级实施调度与传输,并将数据包映射到相应的队列中。若某一优先级的数据包发射速率超过接收端的处理能力,导致接收端可用数据缓冲空间不足,此时设备将会向其前一跳节点发送PFC PAUSE帧。 收到PAUSE帧后,前一跳节点会暂停对应优先级数据包的传输,直至接收到PFC XON帧或等待一定老化时间后再恢复数据流量。通过这种方式,PFC确保了一种类型流量出现拥塞时,不会影响其他类型流量的正常转发,实现同一条链路上不同类型数据包之间互不干扰的顺畅运行。
RDMA优化和RoCE产品选择
在RDMA和RoCE产品优化选择上,英伟达(NVIDIA)基于其在无损以太网实践中的丰富经验,将ECN视为关键的拥塞控制手段。借助硬件加速的Fast ECN支持,系统能够实现快速响应并确保高效的流量管控。同时,通过整合ETS(增强型传输选择)机制和创新的物理缓存优化技术,资源调度得到了针对多元流量模型的精细化调整。 然而,尽管PFC(基于优先级的流量控制)技术带来了一定优势,但其潜在的网络死锁风险也不容忽视。对比分析表明,PFC流控机制在提高网络稳定性和解决由拥塞引发的丢包问题方面效果有限,并暴露出其固有的安全隐患与性能瓶颈。 RDMA专注于大幅提升远程数据传输速率,在实现端到端网络通信中扮演着核心角色。这一过程涵盖了主机侧内核绕过技术、网络卡上的传输层卸载处理,以及在网络侧实施拥塞流控制等复杂环节的深度融合。这些措施共同带来了显著的低延迟、高吞吐量特性,以及低CPU占用率等优势。 然而,当前RDMA的实际应用仍面临可扩展性受限和配置修改过程复杂性等挑战。因此,在不断演进的RDMA与RoCE产品领域中,精准把握技术发展趋势,充分应对各种局限性,是确保无缝集成及保持高性能网络解决方案长期稳定运行的关键。
飞速(FS)如何提供帮助
在构建能够显著提升集群性能的RDMA网络架构时,除了不可或缺的高性能RDMA适配器和强大计算能力的服务器之外,高速光模块、高性能交换机以及高质量线缆等核心组件同样至关重要。 作为专业的信息通信技术产品及解决方案提供商,
飞速(FS)
提供
高性能的交换机
、高速率光模块以及
集成智能技术的网卡
等,帮助企业构建和优化服务平台,以确保高效稳定的服务。 在搭建高性能网络系统的过程中,飞速(FS)凭借其独特优势,在经济效益与运行效能之间实现了理想平衡,成为众多企业部署此类网络时首选的合作伙伴。汇鑫科服隶属于北京通忆汇鑫科技有限公司, 成立于2007年,是一家互联网+、物联网、人工智能、大数据技术应用公司,专注于楼宇提供智能化产品与服务。致力服务写字楼内发展中的中小企业 ,2009年首创楼宇通信BOO模式,以驻地网运营模式为楼宇提供配套运营服务;汇鑫科服始终以客户管理效率为导向,一站式 ICT服务平台,提升写字楼办公场景的办公效率和体验;