RoCE v2,即远程直接内存访问版本2(Remote Direct Memory Access version 2),是Intel推出的一种高速网络技术。该技术通过以太网链路实现服务器之间的数据直接传输,无需通过CPU进行数据复制,从而降低延迟并提高数据传输效率。
RoCE v2工作原理基于RDMA(Remote Direct Memory Access)技术,通过优化TCP/IP协议栈和以太网链路,实现了在以太网环境下高速、低延迟的数据传输。相比第一代RoCE,RoCE v2进一步提升了性能,主要体现在以下几个方面:
1. 协议优化:RoCE v2通过简化TCP/IP协议栈,减少了网络处理开销,提高了数据传输效率。
2. 数据传输效率:RoCE v2在传输数据时,减少了CPU参与的程度,实现了更高的数据吞吐量。
3. 延迟降低:RoCE v2显著降低了网络传输延迟,提高了网络应用性能。
4. 兼容性:RoCE v2与现有网络设备兼容,无需额外投资升级网络硬件。
RoCE v2在金融、云计算、大数据等对网络性能要求较高的领域得到了广泛应用。随着技术的不断发展,RoCE v2有望在未来继续推动网络技术的发展,为用户提供更加高效、低延迟的网络服务。
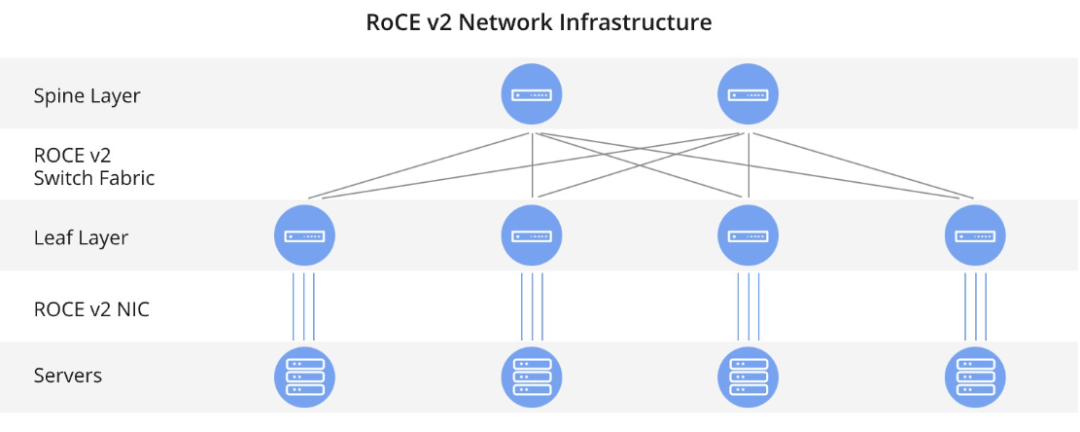
深度解读RoCE v2的核心技术原理-RoCE v2是一种专为实现以太网环境下低延迟、高吞吐量数据传输而设计的RDMA协议。相较于涉及多重处理层次的传统数据传输方式,RoCE v2实现了系统间的直接内存访问机制,最大限度地减少了CPU的参与和降低通信延迟。
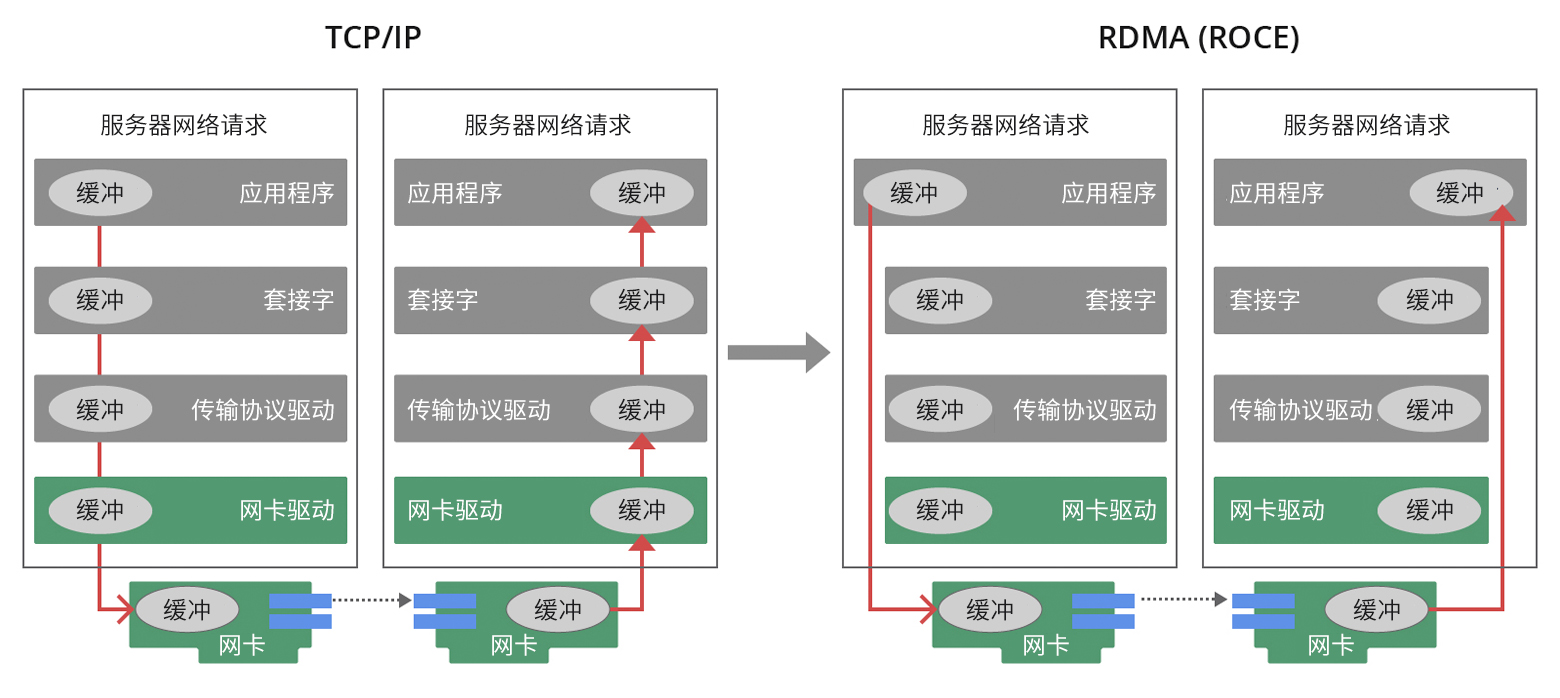
随着企业数字化进程加速,传统数据传输协议面临性能瓶颈,RDMA技术应运而生,通过绕过操作系统内核,实现高效、低延迟的数据传输,显著提升集群性能。RDMA技术在超级计算中心和互联网企业广泛应用,尤其适用于大规模并行计算环境。GPU Direct-RDMA技术进一步优化HPC应用效率,实现跨服务器GPU直接通信。ECN和PFC技术有效管理网络拥塞,保障数据流畅运行。英伟达等企业通过硬件加速和创新技术,...
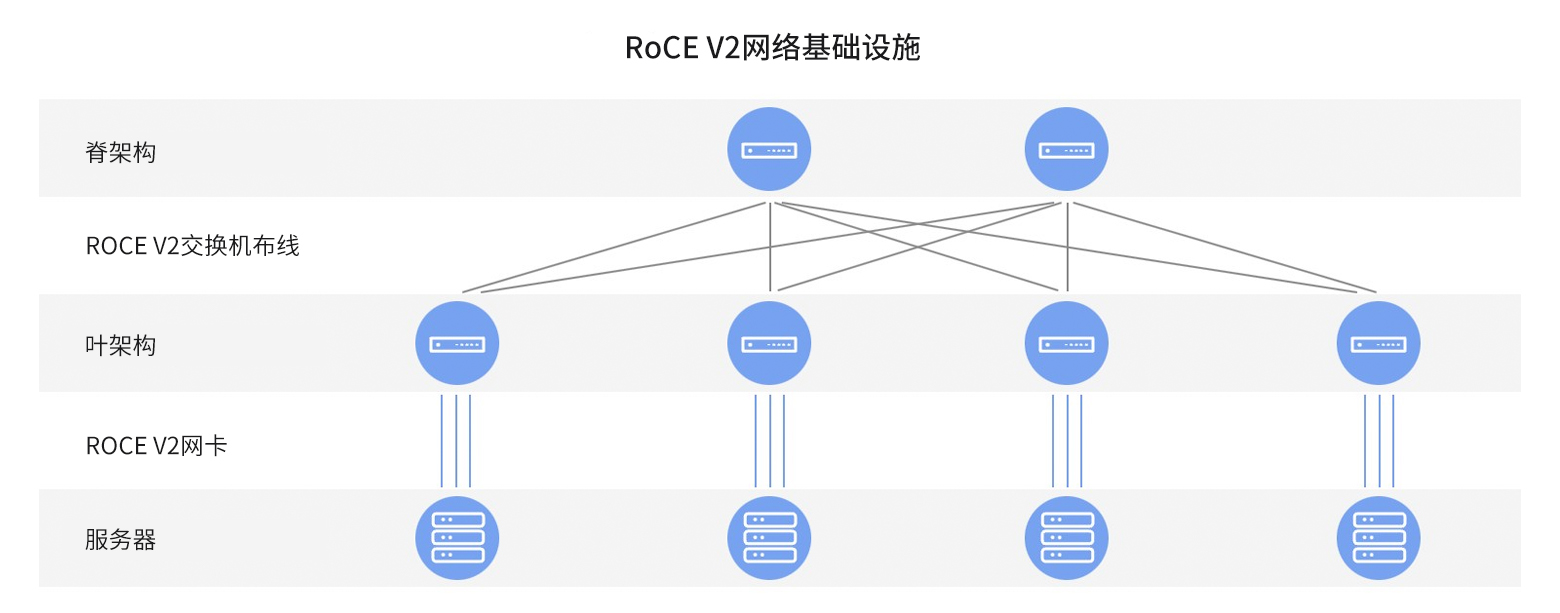
在快速发展的网络技术领域,RoCE v2技术凭借低延迟和高吞吐量的优势,成为提高数据传输效率的关键。RoCE v2通过直接内存访问机制,显著降低CPU参与率,适用于高性能计算和数据中心等场景。相较于InfiniBand,RoCE v2依托以太网基础设施,简化网络管理,兼容TCP/IP协议栈,但依赖以太网DCB特性应对拥塞。InfiniBand则采用专有架构,具备原生拥塞控制和优化路由机制,适用于高...
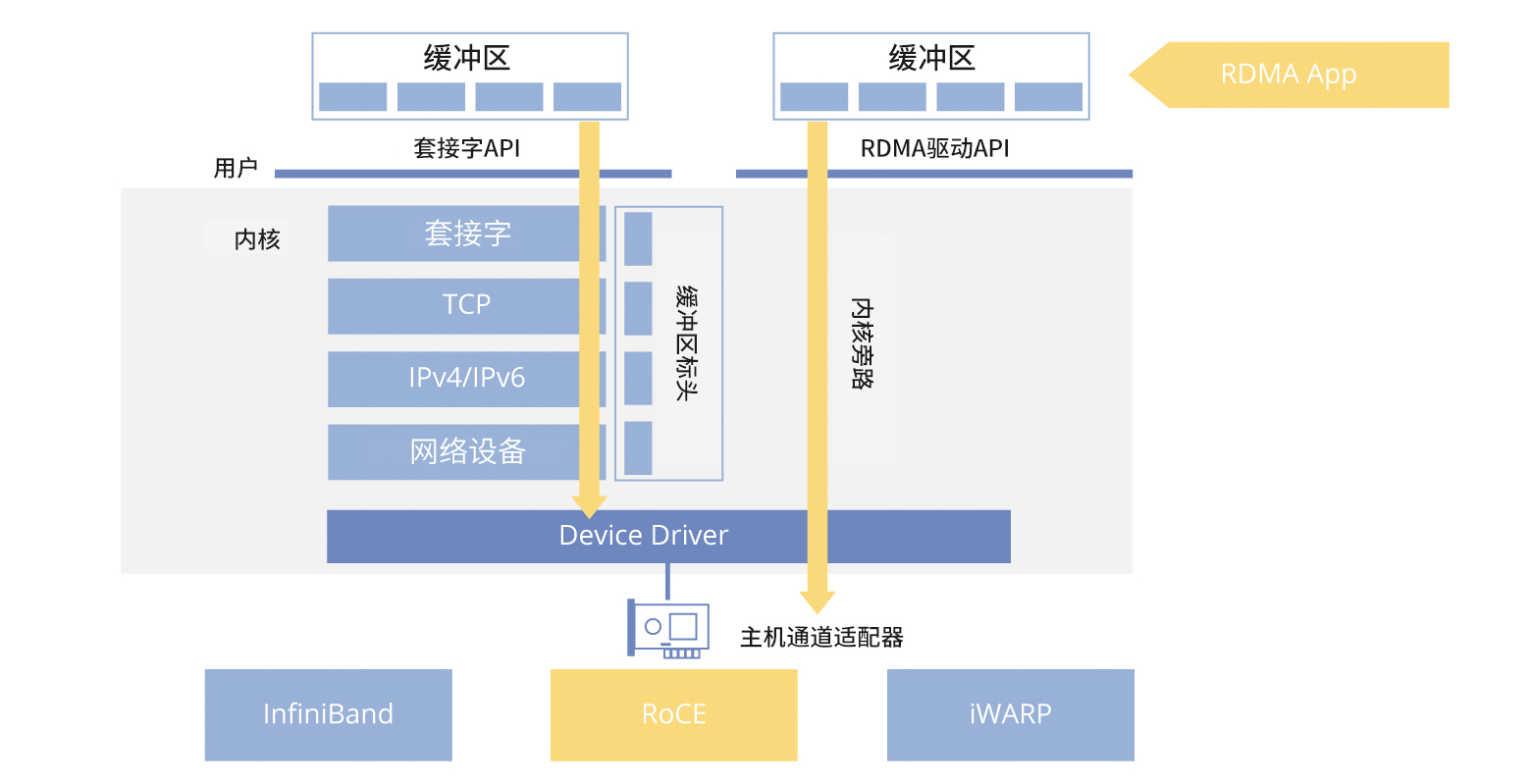
RDMA技术通过绕过操作系统内核,实现高效低延迟的网络通信,降低CPU开销。主要技术手段包括InfiniBand、RoCE和iWARP,其中InfiniBand和RoCE因高性能被广泛应用。InfiniBand网络提供高带宽和低延迟,但成本高;RoCE则更具成本效益。GPU Direct RDMA技术使GPU间直接数据交互,提升大规模模型训练效率。理想配置为每个GPU配备独立InfiniBand网...

在数据时代,传统TCP/IP以太网已无法满足高效网络需求,基于以太网的RDMA(远程直接内存访问)技术应运而生。RDMA允许设备直接数据传输,提升性能和降低延迟。RoCE是RDMA的主要实现,适用于高性能计算和云环境。RoCE v1和v2版本分别支持不同网络层,v2具备更广的应用范围。RoCE优势包括低延迟、低CPU负载和高带宽,但面临拥塞和丢包等问题。实现RoCE需支持RoCE的网卡和驱动程序。...
RoCE v2是以太网环境下的RDMA协议,通过直接内存访问机制降低CPU负担和通信延迟,提升数据传输效率,适用于高性能计算和数据中心。相较于RoCE v1,RoCE v2改进了性能和兼容性,简化网络管理。RoCE网卡是实现高效RDMA操作的关键设备。与InfiniBand相比,RoCE v2依托以太网基础设施,兼容TCP/IP协议,适用于现有网络架构;InfiniBand则采用专有架构,优化低延...
RDMA技术通过绕过操作系统内核层,实现高效低延迟的网络通信,降低CPU开销。关键技术包括InfiniBand、RoCE和iWARP,其中InfiniBand和RoCE因高性能被广泛应用。InfiniBand网络提供高带宽和低延迟,但成本高;RoCE则更具经济性。GPU Direct RDMA技术直接实现GPU间数据交互,提升大规模模型训练效率。理想配置为每个GPU配备独立InfiniBand网卡...

本文主要探讨了流行的GPU/TPU集群网络组网技术,包括NVLink、InfiniBand、ROCE以太网Fabric和DDC网络方案。文章分析了每种技术的优缺点,例如NVLink和InfiniBand的性能优势,但扩展性和成本问题;ROCE以太网的优势在于成熟的生态系统和较低的组网成本,但其拥塞控制机制可能不如IB和NVLink;DDC全调度网络则在解决以太网拥塞问题上具有显著优势,但其成本和供...

流行的GPU/TPU集群网络组网技术包括NVLink、InfiniBand、ROCE以太网Fabric和DDC网络方案等。它们在LLM训练中发挥着重要作用,其中NVLink具有高性能和低开销的特点,但受限于GPU规模;InfiniBand提供卓越的速度和低延迟,但成本较高且扩展性有限;ROCE无损以太网以其成熟的生态、低成本和快速带宽迭代速度,在中大型训练GPU集群中更具优势;DDC全调度网络结合...

RDMA(远程直接内存访问)技术通过直接在远程内存之间传输数据来提高网络效率,尤其在云计算和人工智能领域。RoCEv2是RDMA的一个实现,已经取代TCP成为数据中心后端网络的主流技术。RoCEv2在以太网上运行,面临着队头阻塞、拥塞管理和减少有效吞吐量等挑战,需要通过硬件和软件的定制化解决方案来解决。微软、Oracle和Meta等大厂已通过定制化方案和持续监控解决了这些问题。未来,RDMA技术可...

NVIDIA推出的零接触RoCE(ZTR)技术,结合新的拥塞控制算法RTTCC,允许数据中心在无需交换机配置的情况下部署RoCE,实现大规模RDMA的卓越性能。RTTCC通过硬件监测网络往返时间(RTT),主动调整流量,减少数据包丢失,提高RoCE性能。测试显示,ZTR-RTTCC在性能上与传统RoCE相当,易于部署,为数据中心提供高性能、低延迟的通信解决方案。









