
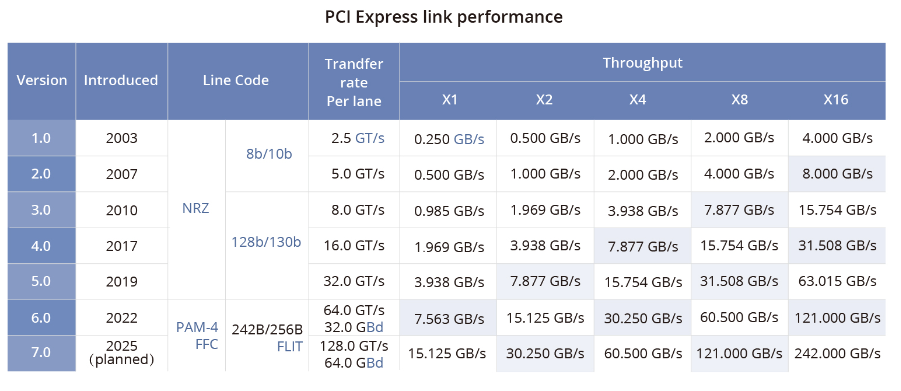
NVLink技术之GPU与GPU的通信-在多 GPU 系统内部,GPU 间通信的带宽通常在数百GB/s以上,PCIe总线的数据传输速率容易成为瓶颈,且PCIe链路接口的串并转换会产生较大延时,影响GPU并行计算的效率和性能。

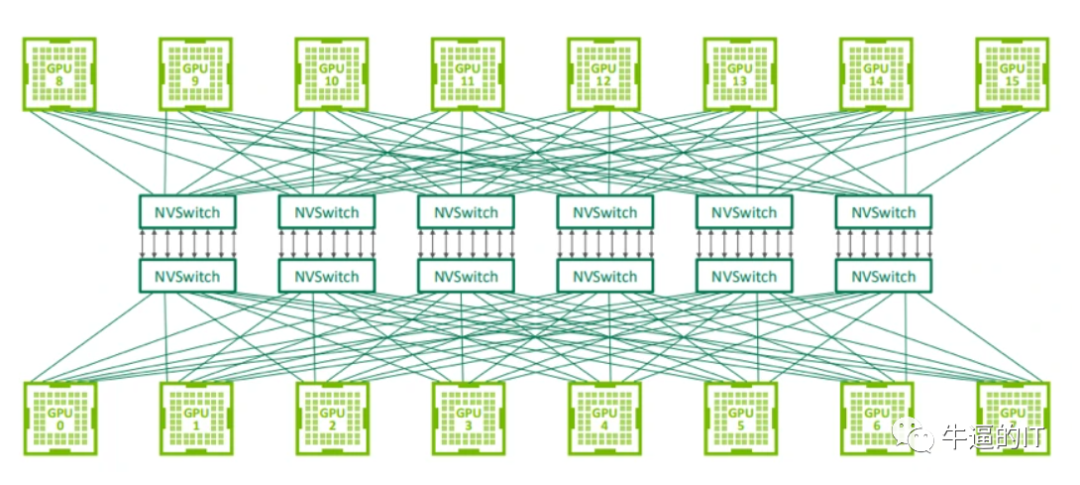
GPU/TPU集群网络组网间的连接方式-用于连接 GPU 服务器中的 8 个 GPU 的 NVLink 交换机也可以用于构建连接 GPU 服务器之间的交换网络。Nvidia 在 2022 年的 Hot Chips 大会上展示了使用 NVswitch 架构连接 32 个节点(或 256 个 GPU)的拓扑结构。
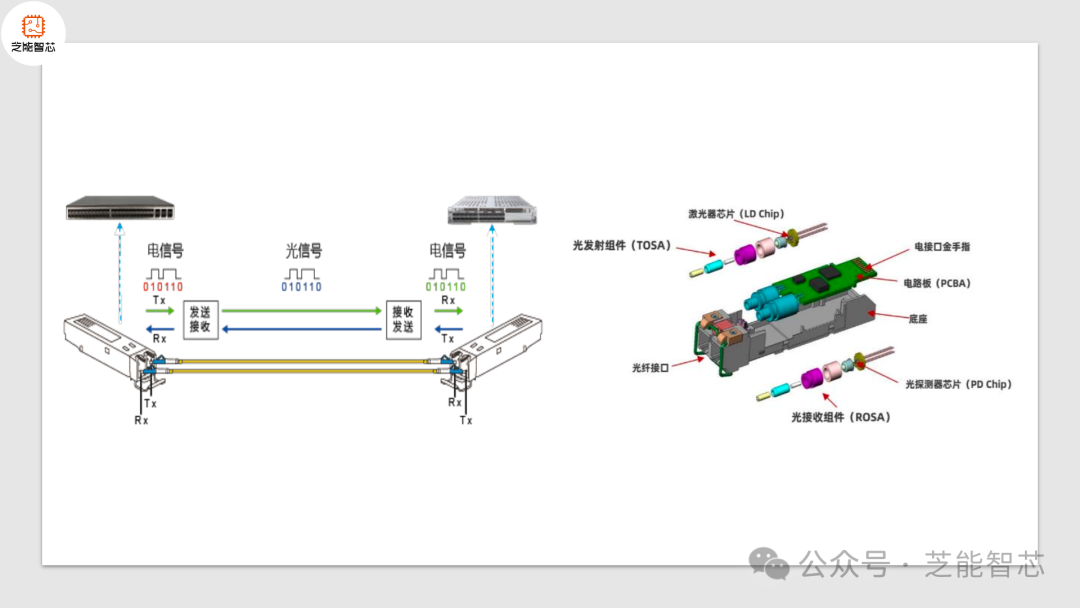

深度剖析AI网络中GPU与光模块配比及需求-市场上存在多种计算光模块与GPU比例的方法,导致结果不相同。造成这些差异的主要原因是不同网络结构中光模块数量的波动。所需的光模块的准确数量主要取决于几个关键因素。
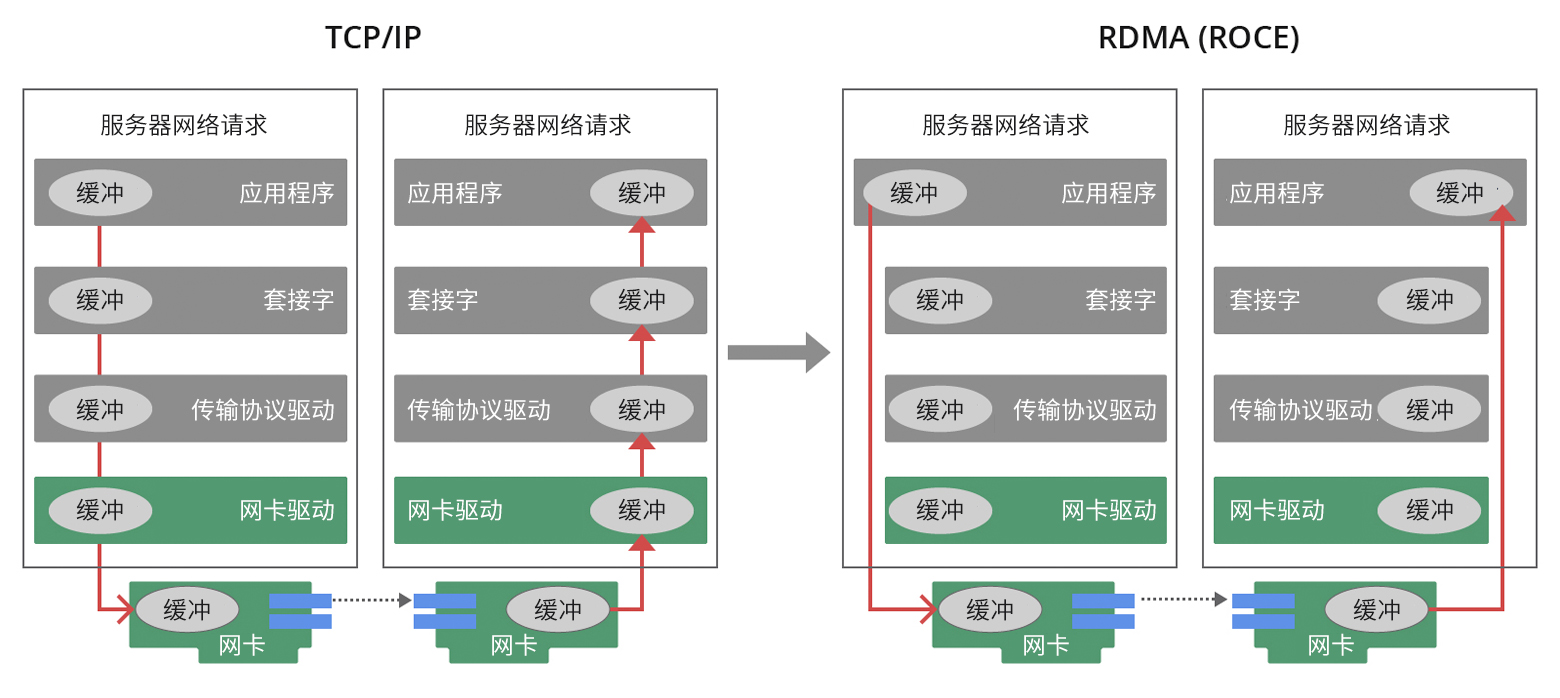
随着企业数字化进程加速,传统数据传输协议面临性能瓶颈,RDMA技术应运而生,通过绕过操作系统内核,实现高效、低延迟的数据传输,显著提升集群性能。RDMA技术在超级计算中心和互联网企业广泛应用,尤其适用于大规模并行计算环境。GPU Direct-RDMA技术进一步优化HPC应用效率,实现跨服务器GPU直接通信。ECN和PFC技术有效管理网络拥塞,保障数据流畅运行。英伟达等企业通过硬件加速和创新技术,...
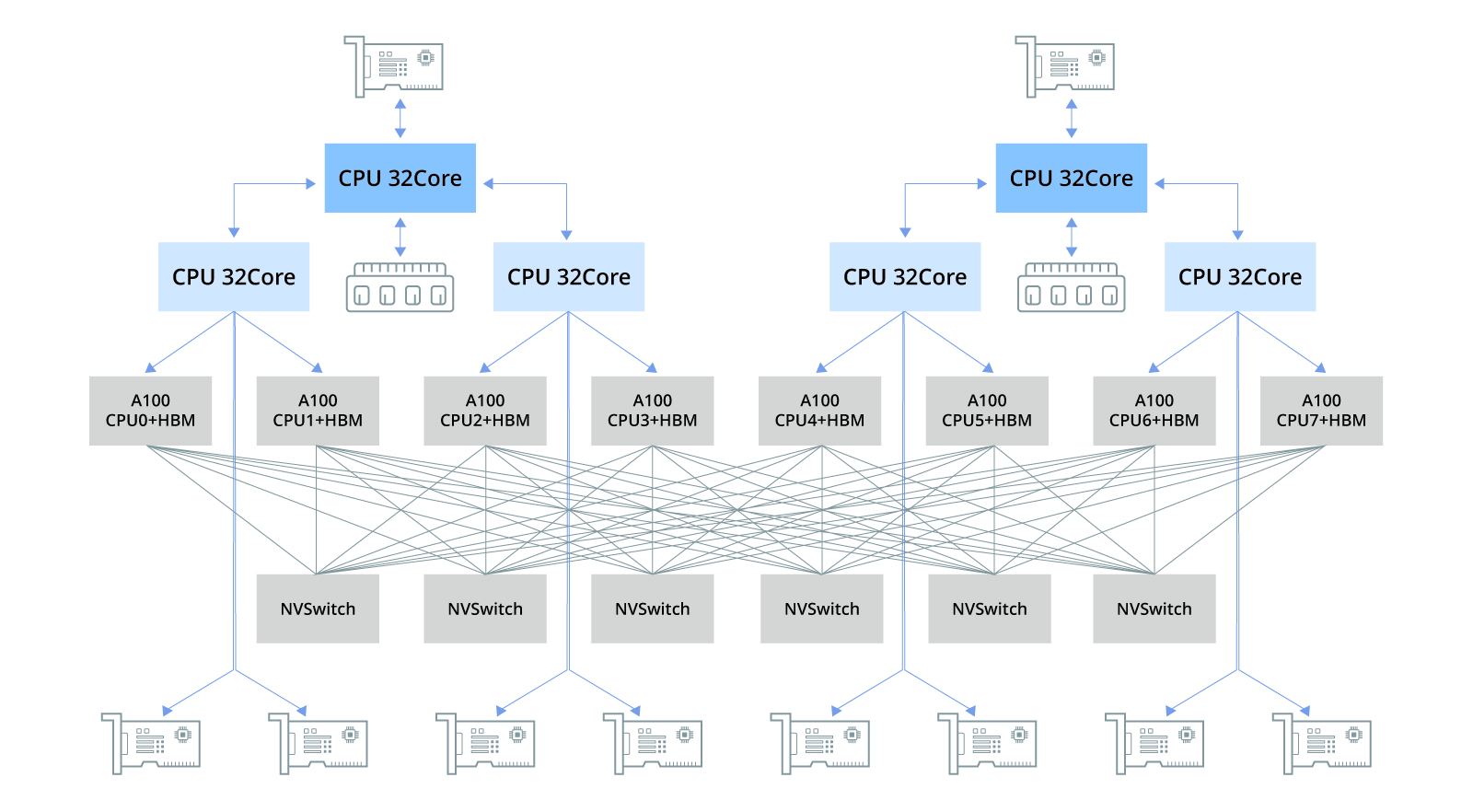
在大规模模型训练领域,高性能GPU服务器基础架构通常由搭载多块GPU(如A100、H100等)的集群系统构成。PCIe总线及交换机芯片实现各组件高效连接,NVLink技术则用于CPU与GPU间及GPU间的点对点连接,历经多代演进,显著提升数据传输速度和带宽性能。NVSwitch芯片支持主机内多GPU低延迟通信,而NVLink交换机则解决跨主机GPU连接问题。此外,高带宽内存(HBM)技术突破传统内...
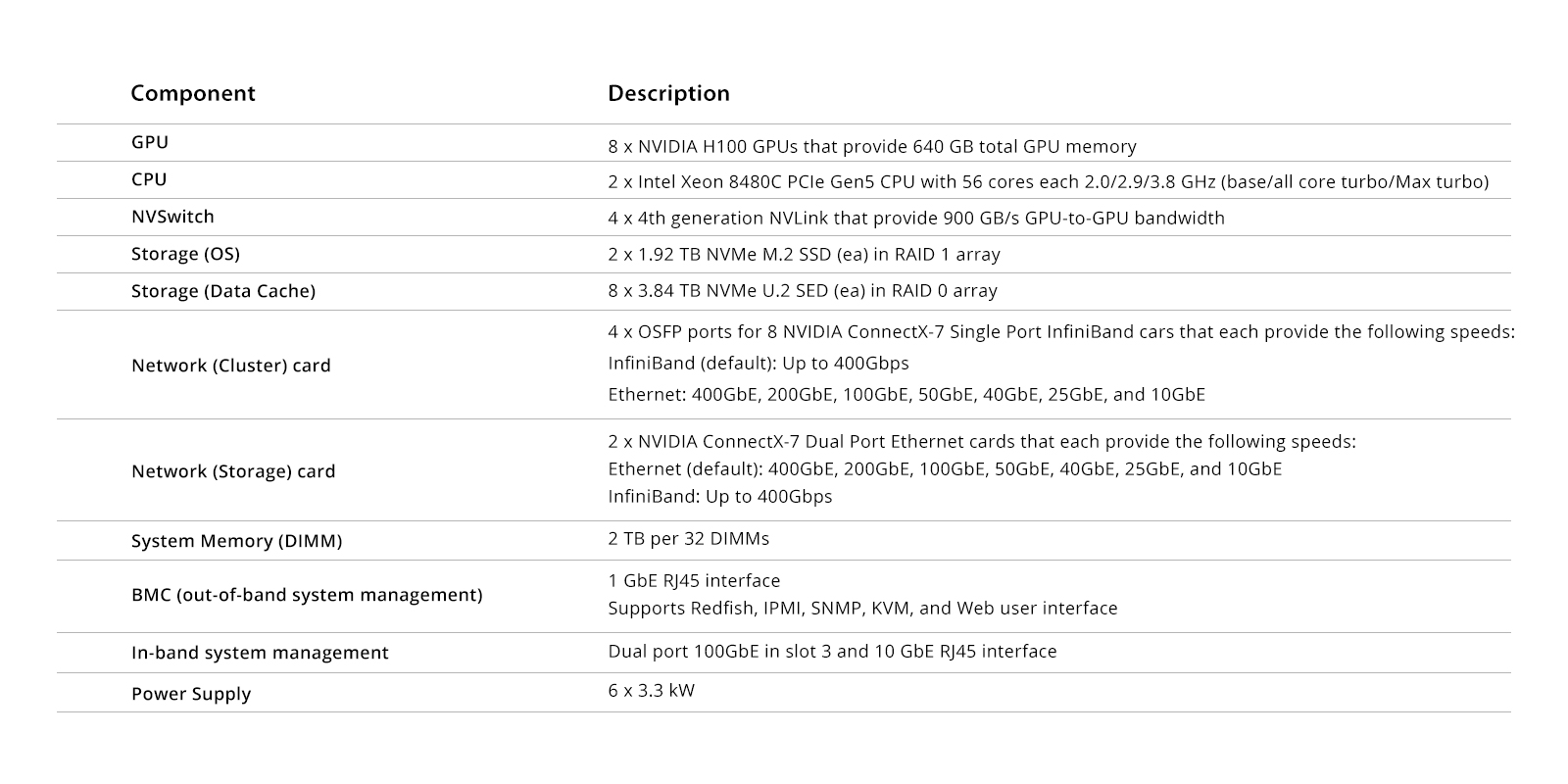
NVIDIA DGX H100系统是专为高性能计算(HPC)设计的多功能解决方案,覆盖从数据分析到推理的应用场景。系统包含NVIDIA Base Command和软件套件,以及专业建议。硬件方面,DGX H100具备8U机架安装、最大10.2KW电源规格,支持高速网络连接。主要组件包括CPU主板托盘和GPU托盘,前者提供2 TB内存和多种管理系统,后者配备8个H100 GPU,提供640 GB G...

数据处理单元(DPU)作为计算领域的新兴支柱,与CPU和GPU并列,专门用于加速数据中心网络、存储和计算任务。DPU集成了强大的处理能力、高速数据传输和多功能加速,有效提升数据处理效率。相较于CPU的通用性和GPU的并行计算优势,DPU专注于数据中心内的数据移动和处理,优化网络功能加速。其应用涵盖数据包处理、流量管理和安全加密,尤其在SmartNIC中发挥关键作用。真正的DPU需具备十种硬件加速能...
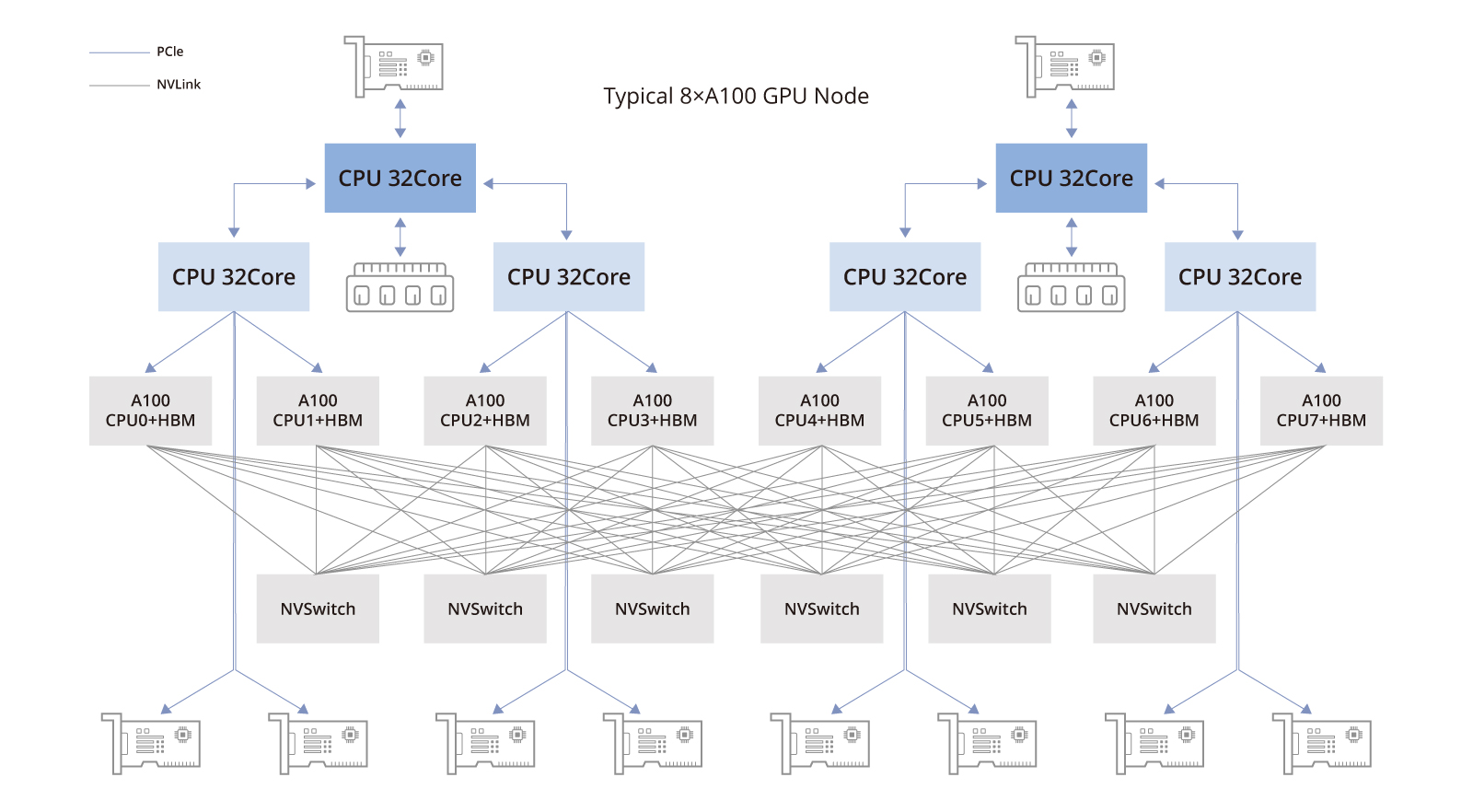
在大型模型训练中,多GPU服务器集群架构广泛应用。本文深入探讨了常见GPU系统架构,以NVIDIA A100和A800为例,详解其拓扑结构、组件功能及网络连接。A100拓扑包括CPU、存储网络适配卡、PCIe交换芯片、NVSwitch芯片和GPU等,强调NVSwitch对GPU间高速通信的重要性。A800则在NVLink通道数量上有所减少,影响带宽。文章还分析了存储网络卡的作用,如读写分布式数据和...
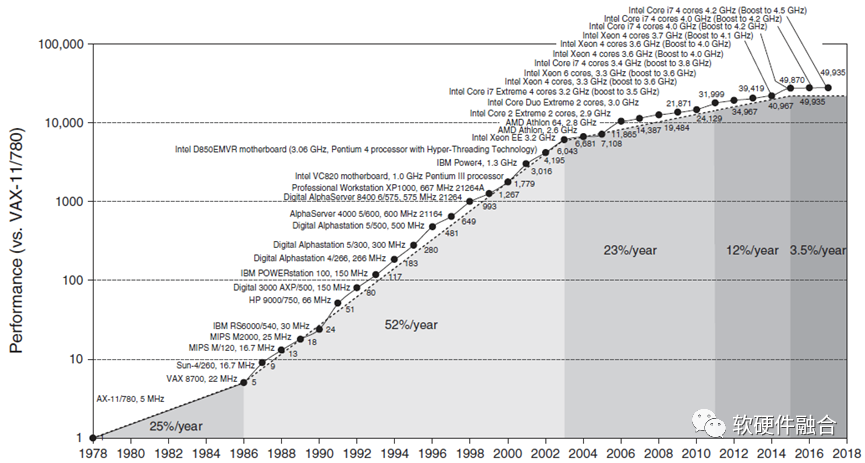
国家发改委等部门发布《全国一体化大数据中心协同创新体系算力枢纽实施方案》,提出建设八大国家算力网络枢纽节点,启动“东数西算”工程。算力已成为全球战略竞争焦点,美国、中国、欧洲和日本纷纷布局。本文通过“预见·第四代算力革命”系列文章,分析CPU、GPU和DSA三大主流计算平台的优劣势。CPU作为通用处理器,灵活性高但性能瓶颈明显;GPU擅长并行计算,性能优于CPU但不及DSA和ASIC;DSA针对特...

摩尔线程宣布其AI旗舰产品夸娥智算集群解决方案升级,从千卡扩展至万卡规模,专为万亿参数大模型训练设计,旨在打造国产通用加速计算平台。夸娥万卡集群不仅提供超大算力和高稳定性,还具备极致优化和生态友好特性,适用于多架构大模型训练。面对AI大模型扩展趋势,万卡集群成为行业标配。国际巨头如Google、Meta及国内字节跳动、阿里巴巴等均在推进超万卡集群建设。摩尔线程强调万卡集群建设虽复杂,但坚信其为正确...

本文探讨了流行的GPU/TPU集群网络技术,包括NVLink、InfiniBand、ROCE以太网和DDC网络方案,分析了它们在LLM训练中的连接方式和作用,以及各自的优缺点和适用场景。


 企服商城
企服商城













