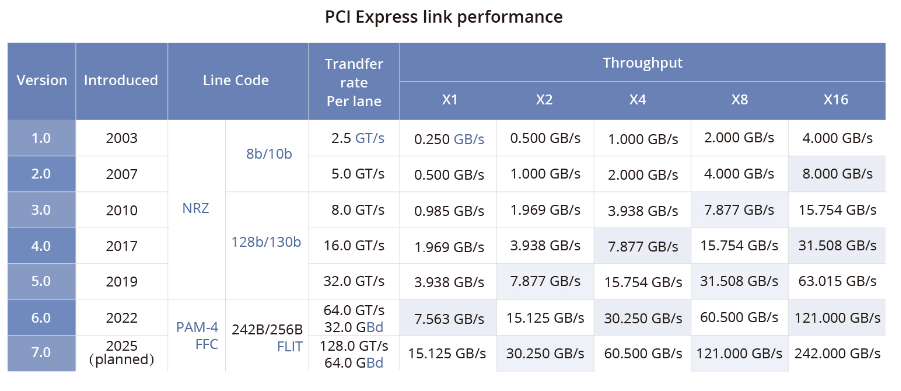
什么是NVIDIA?InfiniBand网络VSNVLink网络-NVSwitch物理交换机将多个NVLink GPU服务器连接成一个大型Fabric网络,即NVLink网络,解决了GPU之间的高速通信带宽和效率问题。
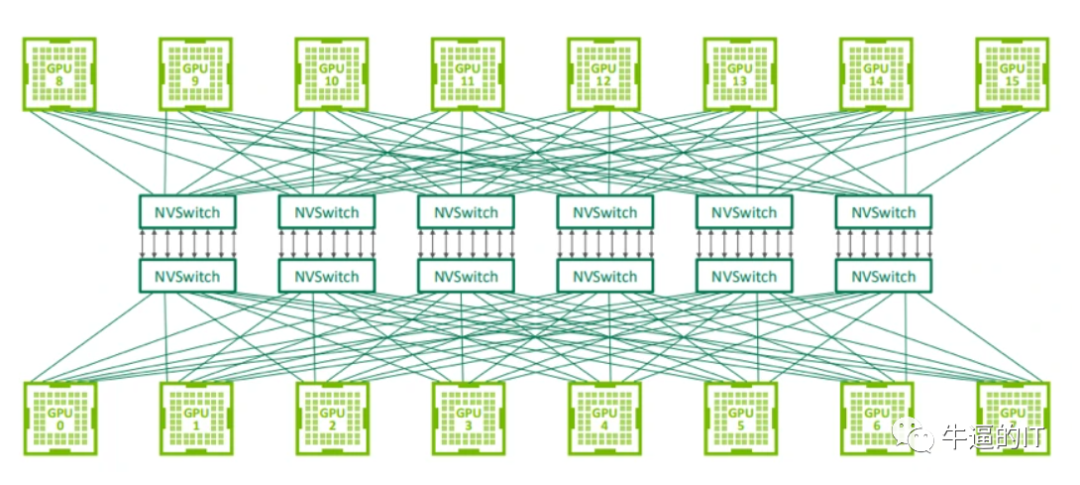
GPU/TPU集群网络组网间的连接方式-用于连接 GPU 服务器中的 8 个 GPU 的 NVLink 交换机也可以用于构建连接 GPU 服务器之间的交换网络。Nvidia 在 2022 年的 Hot Chips 大会上展示了使用 NVswitch 架构连接 32 个节点(或 256 个 GPU)的拓扑结构。

深入探索InfiniBand网络、HDR与IB技术-InfiniBand和以太网之间的延迟对比可以分为两个主要组成部分。首先,在交换机层面上,以太网交换机在网络传输模型中作为第2层设备运行,通常采用MAC表查找寻址和存储转发机制(某些产品可能采用InfiniBand的直通技术)。

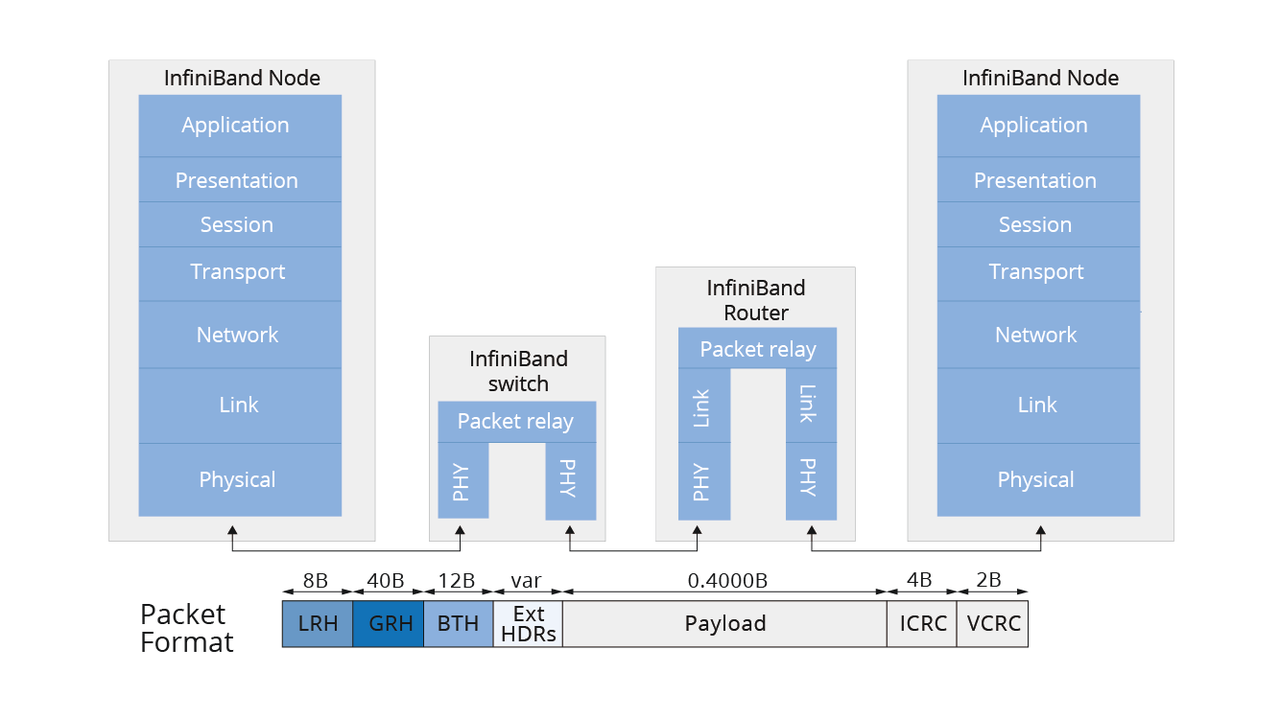
InfiniBand是一种由多家科技巨头联合开发的新型通信互连技术,采用数据分组交换通信协议,旨在解决传统总线架构的距离和性能问题。它通过高速串行I/O链路连接服务器、存储和网络设备,支持多链路带宽选项和冗余性,提供更高的带宽和更好的可扩展性。
随着高性能计算需求增长,InfiniBand技术因其高带宽和低延迟优势,成为数据中心优选。InfiniBand支持多种线缆类型,最大数据包4K,吞吐率高达300GB/s。品牌如飞速(FS)推出相关产品,如100G QSFP28 IB光模块,助力网络搭建。InfiniBand在服务器虚拟化和云计算中表现突出,提升CPU效率,支持大数据处理。其高速度和可扩展性,使网络架构简化,延迟降低。未来,Infi...
InfiniBand和以太网作为互连技术,各有特点。InfiniBand在高性能计算中表现突出,具备高可靠性、低延迟和高带宽,广泛用于超级计算机和GPU服务器。其技术不断迭代,从SDR到NDR,速率大幅提升。以太网则侧重于低成本和广泛兼容性,适用于企业网络和互联网接入。两者在带宽、延迟、可靠性和网络模式上存在差异。InfiniBand更适合对延迟敏感的场景,而以太网则灵活且易于扩展。随着计算需求增...

ChatGPT对技术的影响引发了对高性能计算和多模态技术的关注,OpenAI推出的GPT-4显著推动了各领域发展。大规模模型训练需大量计算资源和高速网络,端到端InfiniBand网络成为理想选择。训练大型语言模型(LLM)面临数据传输和通信瓶颈,环形全约减和双阶段环形算法优化了GPU通信。NVIDIA集体通信库(NCCL)在多GPU和多节点通信中发挥关键作用。InfiniBand网络提供高带宽、...
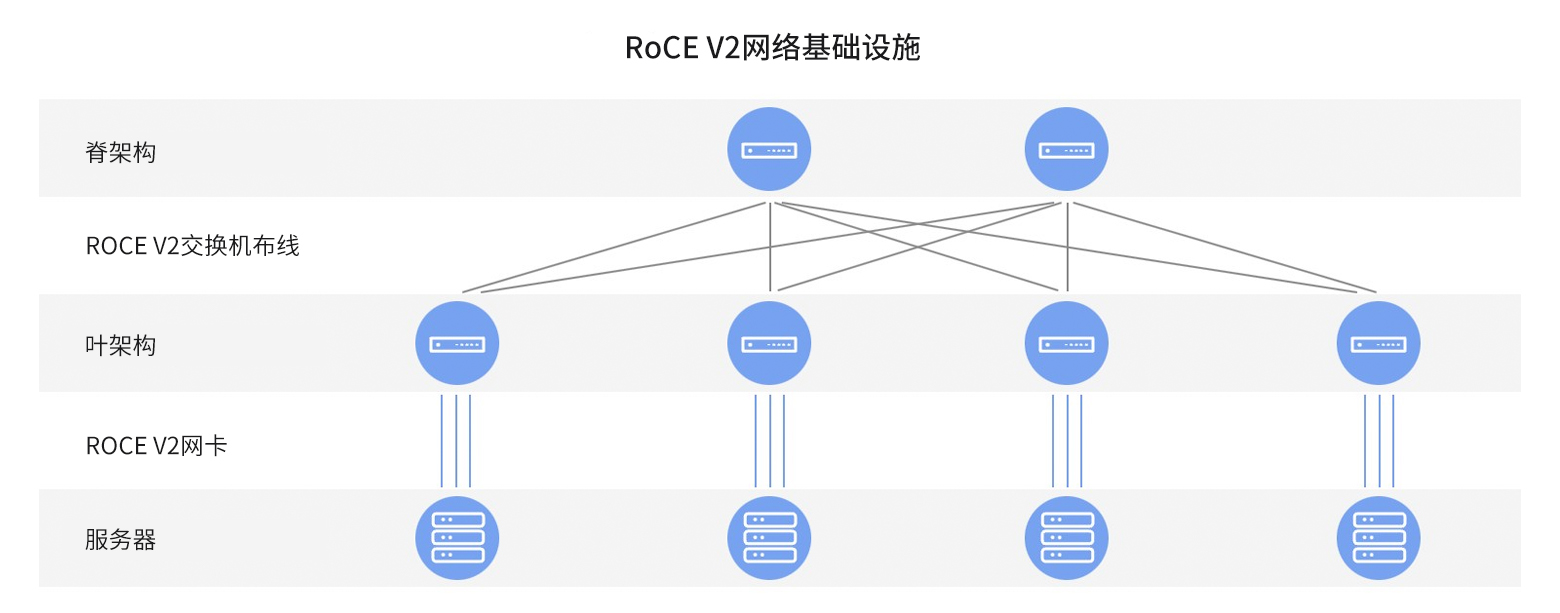
在快速发展的网络技术领域,RoCE v2技术凭借低延迟和高吞吐量的优势,成为提高数据传输效率的关键。RoCE v2通过直接内存访问机制,显著降低CPU参与率,适用于高性能计算和数据中心等场景。相较于InfiniBand,RoCE v2依托以太网基础设施,简化网络管理,兼容TCP/IP协议栈,但依赖以太网DCB特性应对拥塞。InfiniBand则采用专有架构,具备原生拥塞控制和优化路由机制,适用于高...
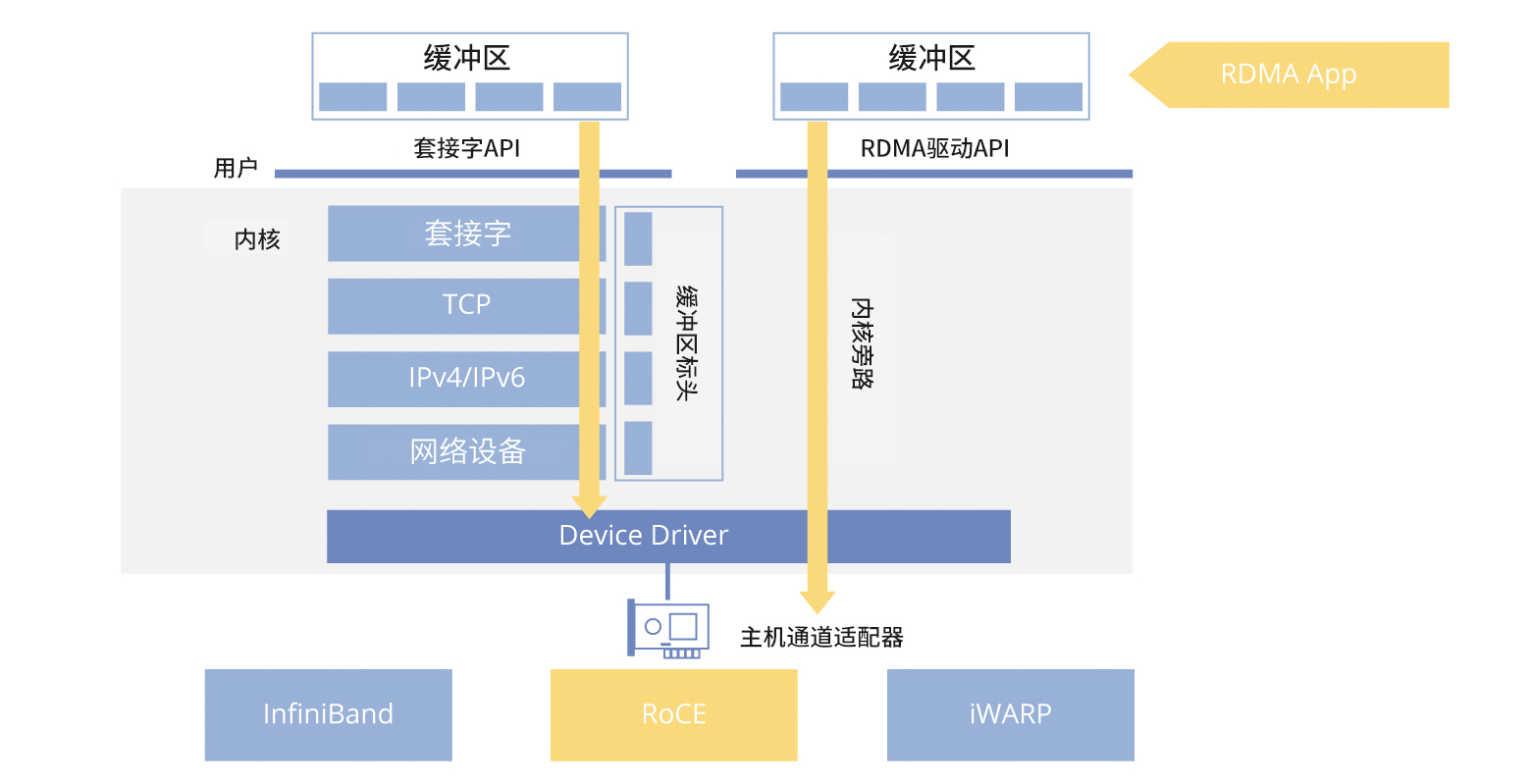
RDMA技术通过绕过操作系统内核,实现高效低延迟的网络通信,降低CPU开销。主要技术手段包括InfiniBand、RoCE和iWARP,其中InfiniBand和RoCE因高性能被广泛应用。InfiniBand网络提供高带宽和低延迟,但成本高;RoCE则更具成本效益。GPU Direct RDMA技术使GPU间直接数据交互,提升大规模模型训练效率。理想配置为每个GPU配备独立InfiniBand网...

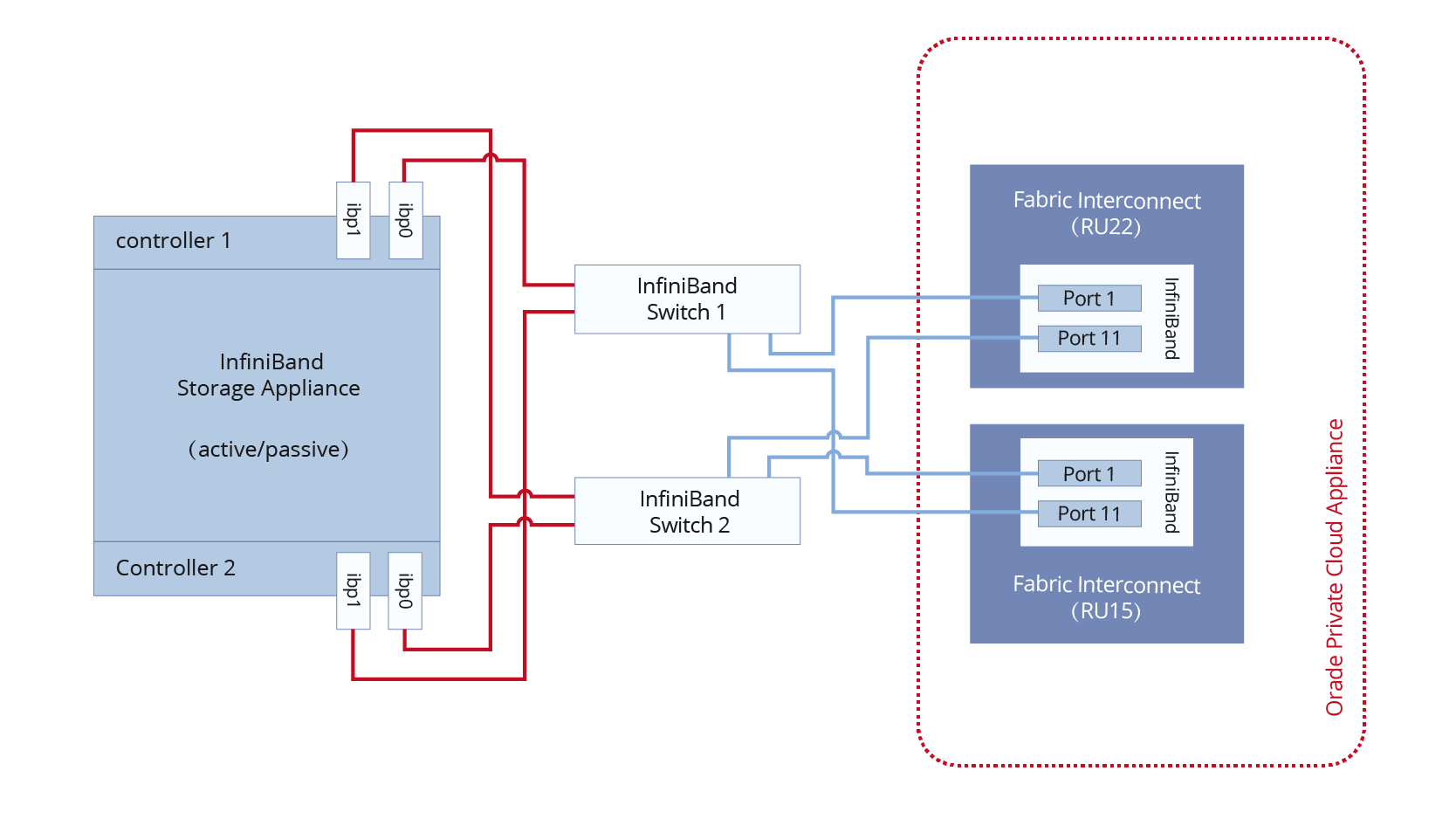
InfiniBand作为一种高性能计算和云基础设施的核心技术,凭借其高带宽、低延迟和可扩展性,成为HPC和超大规模数据中心的首选。相较于以太网,InfiniBand在速率、带宽、延迟和网络可靠性方面表现更优,支持FDR、EDR、HDR和NDR等多种传输速率,适用于GPU加速计算和存储应用。其在TOP500系统中的占比高达44.4%,远超以太网。InfiniBand技术由IBTA标准化,确保了组件间...
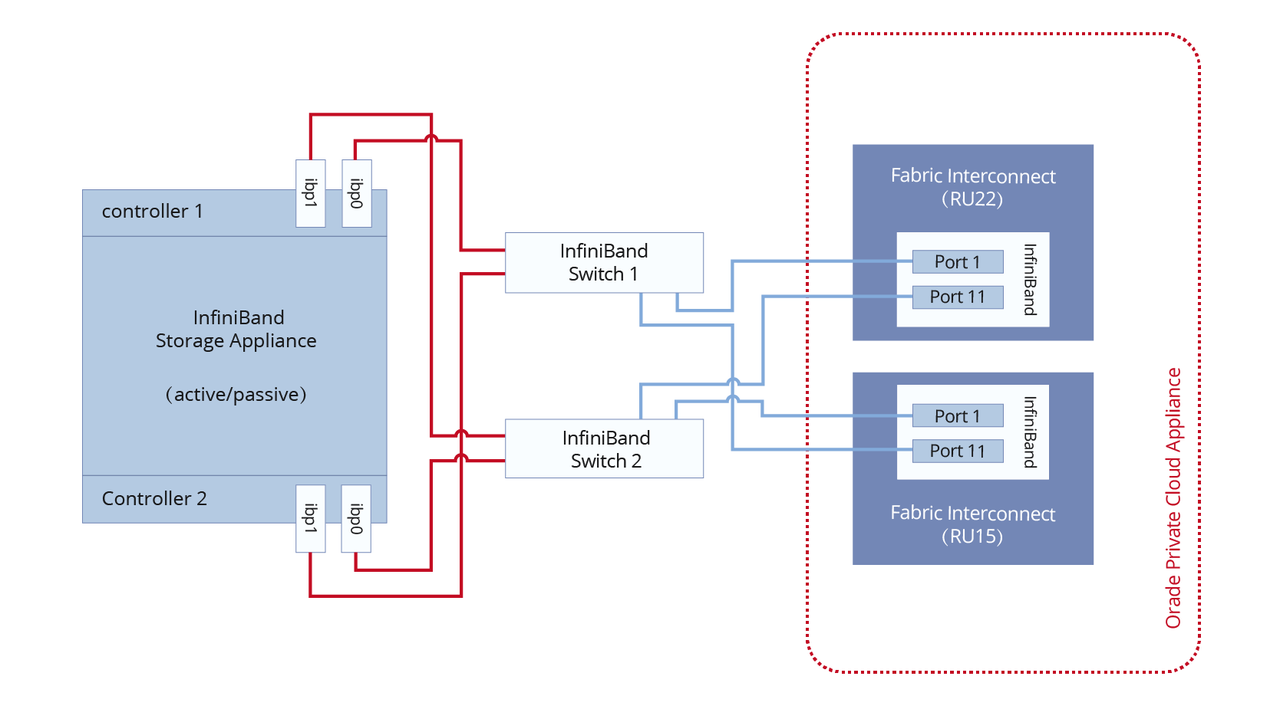
本文深入探讨了InfiniBand和光纤通道作为存储协议的区别,旨在帮助读者在网络存储技术上做出明智决策。存储协议在数据传输效率、可靠性、兼容性和扩展性方面至关重要。InfiniBand以其高性能、低延迟和灵活的互连拓扑适用于高性能计算和大数据分析,而光纤通道则以其高可靠性、稳定性和兼容性广泛应用于存储网络。选择存储协议需考虑技术特点、速率性能、环境兼容性、扩展性和成本等因素。InfiniBand...

InfiniBand是一种开放标准的高性能网络技术,用于连接CPU/GPU服务器、存储设备等,提供高带宽和低延迟。其网络结构包括主机通道适配器(HCA)、交换机、路由器等组件,通过子网管理器(SM)实现高效管理。InfiniBand具备低延迟、高可扩展性和容错特性,支持RDMA和GPU Direct,优化数据传输。相比传统以太网,InfiniBand在性能、可扩展性和可靠性上更具优势。飞速(FS)...
RoCE v2是以太网环境下的RDMA协议,通过直接内存访问机制降低CPU负担和通信延迟,提升数据传输效率,适用于高性能计算和数据中心。相较于RoCE v1,RoCE v2改进了性能和兼容性,简化网络管理。RoCE网卡是实现高效RDMA操作的关键设备。与InfiniBand相比,RoCE v2依托以太网基础设施,兼容TCP/IP协议,适用于现有网络架构;InfiniBand则采用专有架构,优化低延...
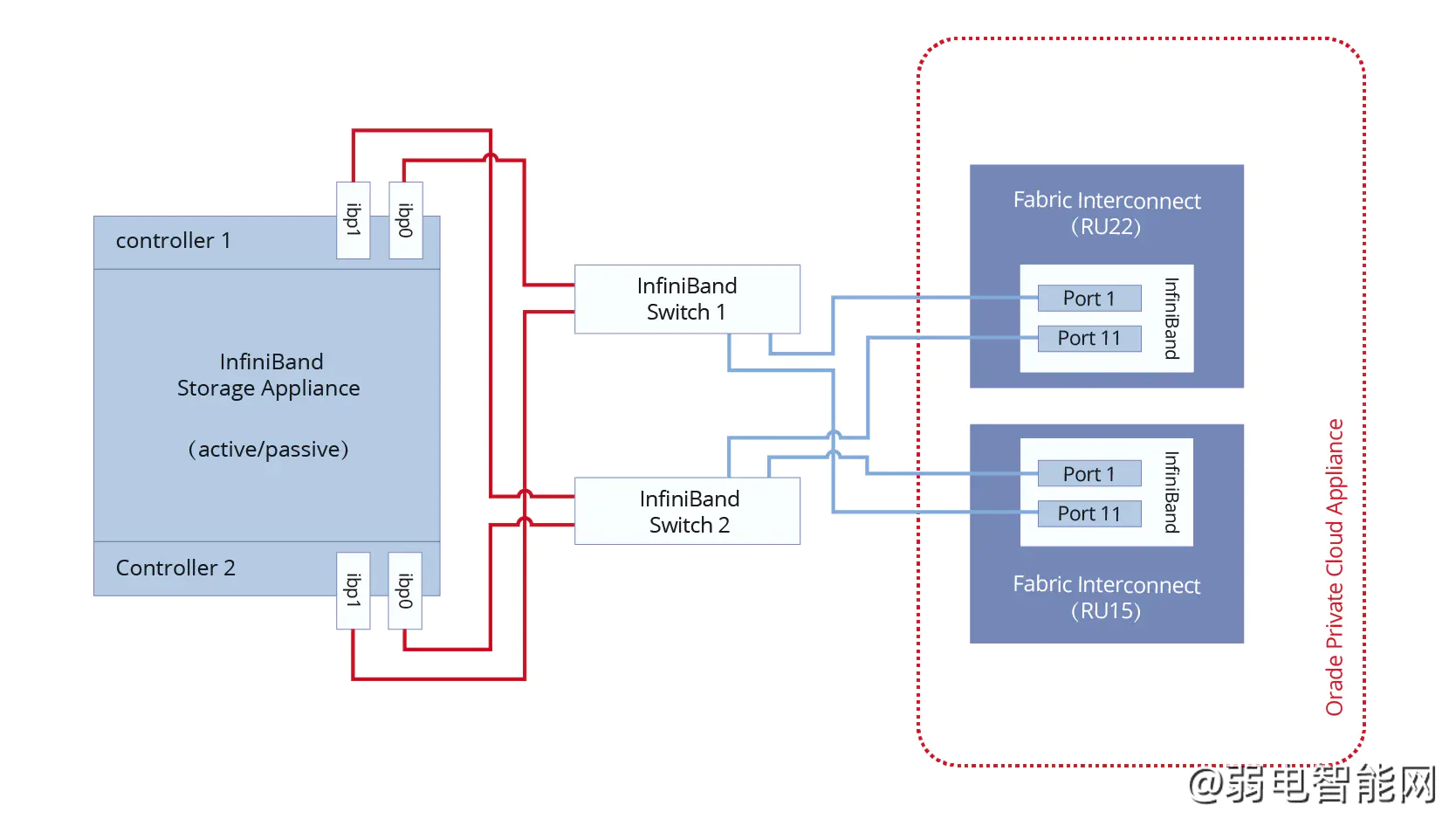
近年来,InfiniBand和光纤通道在数据存储应用中备受关注,企业追求高吞吐量、低延迟的网络基础设施。两者在带宽、延迟、IOPS等参数上各有优势。InfiniBand适用于高性能计算,具有高吞吐量和低延迟特点,常用于超级计算机互连;光纤通道则是SAN网络的传统选择,低延迟、高带宽且易于管理。InfiniBand采用RDMA技术,在速度和可扩展性上优于光纤通道,但成本较高;光纤通道则在维护和速率上...
RDMA技术通过绕过操作系统内核层,实现高效低延迟的网络通信,降低CPU开销。关键技术包括InfiniBand、RoCE和iWARP,其中InfiniBand和RoCE因高性能被广泛应用。InfiniBand网络提供高带宽和低延迟,但成本高;RoCE则更具经济性。GPU Direct RDMA技术直接实现GPU间数据交互,提升大规模模型训练效率。理想配置为每个GPU配备独立InfiniBand网卡...

本文探讨了流行的GPU/TPU集群网络技术,包括NVLink、InfiniBand、ROCE以太网和DDC网络方案,分析了它们在LLM训练中的连接方式和作用,以及各自的优缺点和适用场景。


 企服商城
企服商城













